Indian language computing has evolved from ASCII-based font encoding to Unicode standardization. This article explains how text was represented in Indian languages before Unicode, the problems with ASCII-based fonts, and why Unicode became necessary. It covers various input methods developed for typing Indian languages and demonstrates how Unicode solved the compatibility issues between different systems.
Table of Contents
- What is Unicode?
- Unicode is more than just Codepoints!!
- What is an Input Method?
- What is a Font?
- The Ghost of ASCII Past
- Conclusion
What is Unicode?
Unicode is the universal coding scheme for text. Every character in every language is mapped to a unique code-point. This scheme is followed by all digital devices including Personal Computers, Smart Phones, Television sets. It enables seamless communication between all devices. This is why you are able to read the same email content on phone and computer.
There exists an unique Unicode code-point for every coded-character set. The code is a variable length binary code. For easy readability they are often represented in hexadecimal format also.
Some Hindi (Devanagari) Unicode Characters
Vowels (स्वर)
| Character | Description | Hexadecimal | Binary |
|---|---|---|---|
| अ | a | U+0905 | 0000 1001 0000 0101 |
| आ | aa | U+0906 | 0000 1001 0000 0110 |
Vowel Signs (मात्रा)
| Character | Description | Hexadecimal | Binary |
|---|---|---|---|
| ा | aa | U+093E | 0000 1001 0011 1110 |
| ि | i | U+093F | 0000 1001 0011 1111 |
Consonants (व्यंजन)
| Character | Description | Hexadecimal | Binary |
|---|---|---|---|
| क | ka | U+0915 | 0000 1001 0001 0101 |
| ख | kha | U+0916 | 0000 1001 0001 0110 |
Special Characters
| Character | Description | Hexadecimal | Binary |
|---|---|---|---|
| ़ | Nukta | U+093C | 0000 1001 0011 1100 |
Unicode is more than just Codepoints!!
This universal coding scheme is the backbone of modern Natural Language Processing, Multilingual capabilities of Computers and even Generative AI and LLMs.
Given a character code, any computer application can instantly identify if it belongs to a specific script, whether it is a vowel, vowel sign, if it can occur in the beginning of a word/sentence etc.
Script Grammar
For example the vowel sign ि, has meaningful existence only if it follows a consonant.
क + ा = का
क + ि = कि
Complex Rendering
Some vowel signs in Indic languages are displayed on the screen in a different order than they are stored on the computer.
-
Glyph Reoder
eg: क + ि = कि. (Data oder is different than visual order). This reordering is handled by fonts and rendering engines.
-
Complex Conjuncts
eg: The conjunct क्ष (ksha) is formed by combining: क + ् + ष = क्ष
Note that while these three Unicode code points are encoded separately, font rendering engines apply shaping rules to display them as a single ligature/conjunct character.
Collation
You can sort a list of names programmatically on your computer because there are collation libraries based on Unicode codepoints.
Translation
AI based Translation systems are trained to convert between languages and they are trained on unicode text.
Text Alignment
Hyphenation libraries work on Unicode character properties. A line flow should not be broken between a consonant and its associated vowel sign. You can not expect to break a line after क and the following ी on the next line
What is an Input Method ?
Any software that allows you input text into your digital device is an input method.
Typewriters
On your personal computer (used in India), and its associated physical keyboard, the key strokes are mapped into unicode codeponts corresponding to English alphabets.
| Character | Unicode Name | Hexadecimal | Binary |
|---|---|---|---|
| A | LATIN CAPITAL LETTER A | U+0041 | 0000 0000 0100 0001 |
| & | AMPERSAND | U+0026 | 0000 0000 0010 0110 |
When it comes to inputting Indian languages on your computer, you need software intermediates, that maps your regular physical keyboard strokes into Unicode codepoints for अ or ख.
💡Even if your keystroke is on D or K on your keyboard, the input method ultimately converts it to the intended unicode code point corresponding to the script you intend to type
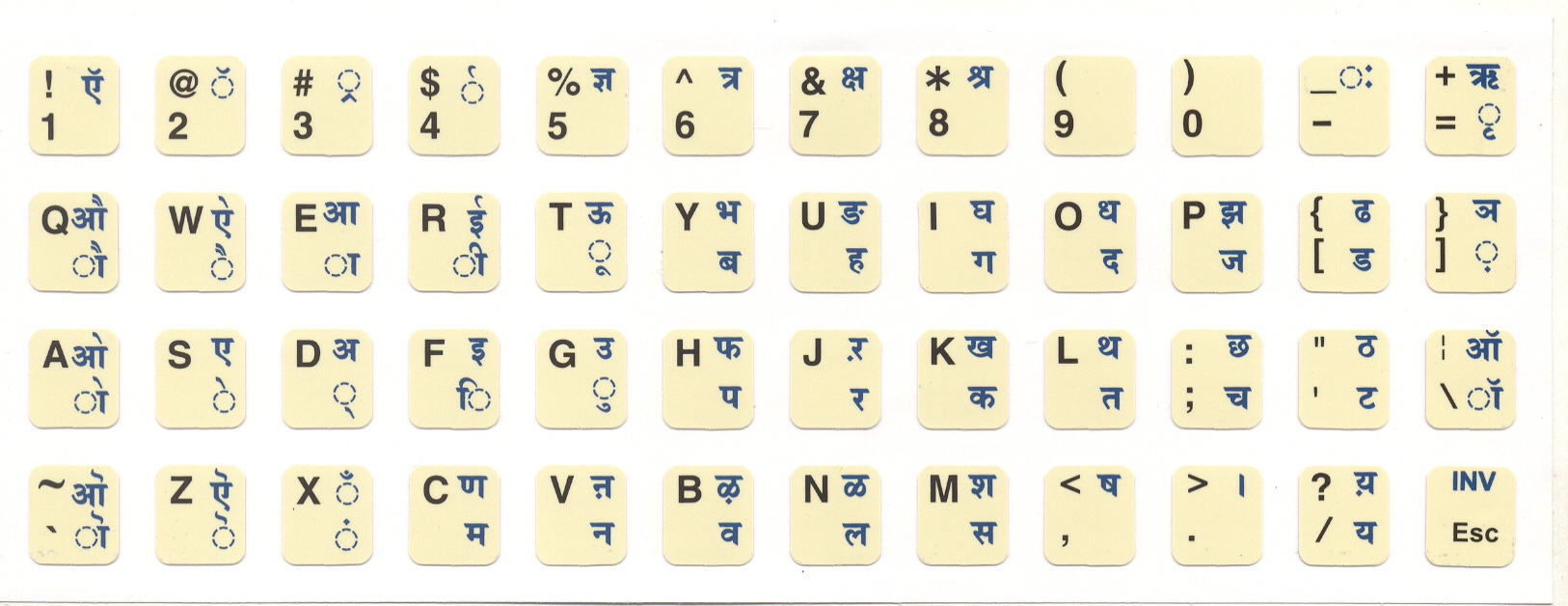
There are different methods to map your regular English keyboard to Indian languages. They are broadly called in-script and phonetic typing.
-
There is one-to-one mapping between the keys on your computer and the Devanagari Characters. You byheart the mapping and type the document
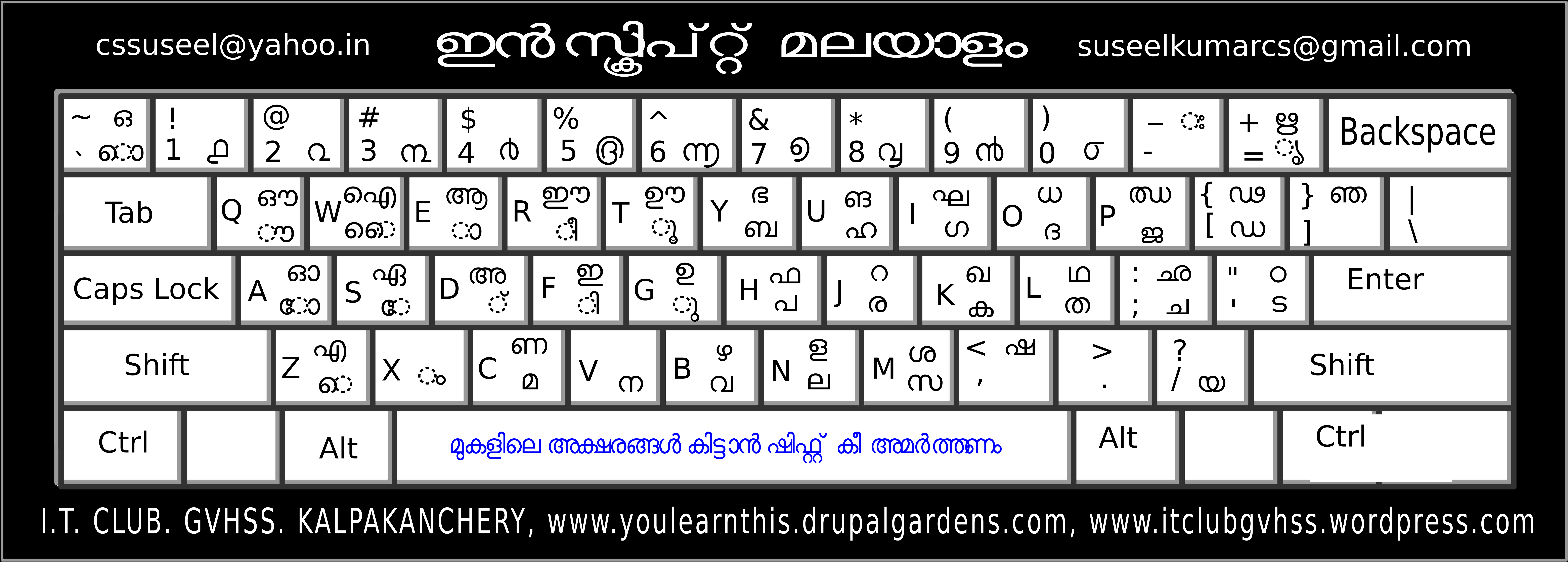
A similar mapping is available for Malayalam as shown in the image below.
-
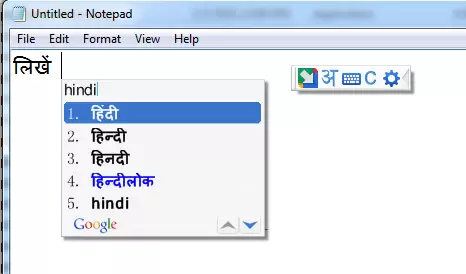
Phonetic
You roughly type the hinglish equivalent and the input methods converts to the Devanagari Unicode.
Handwriting Input
The handwriting recognition software maps the finger strokes to unicode characters sequences. For example if you draw क्ष on your handwriting input method, it converts it into the sequence क + ् + ष and stores on your device.
Voice Input
Your speech is converted into unicode text using a speech recognition engine.
What is a Font?
A font is a software that enables you to ‘see’ what is the text stored in you computer in a visual form.

When a font (software) finds the stored code point U+090B, it shows the shape ऋ on the display.
A Devanagari font contains the mapping of every Devanagari codepoint to its appropriate visual form.
Every visual form may not have a unique codepoint. For example the conjucts are formed from basic consonants with the virama sign in between as in the case for : क + ् + ष = क्ष.
While you see क्ष on the screen, it is the sequence क ् ष, under the hoods. Any NLP application will be processing the sequence क ् ष.
The Ghost of ASCII Past
Unicode came into existence in 1991, with the goal of encoding every writing system of the world. Prior to Unicode, text encoding was all about 128 codepoints, which included English alphabets and some control characters. It forms the foundation of most modern character encoding schemes, including Unicode, which is backward compatible with ASCII. First 32 characters in ASCII are control characters and the rest are printable English characters and symbols.
- The ASCII Codepoint Chart for some printable characters
Decimal Hex Binary Character 32 20 0010 0000 (space) 33 21 0010 0001 ! 34 22 0010 0010 " 47 2F 0010 1111 / 48 30 0011 0000 0 49 31 0011 0001 1 50 32 0011 0010 2 69 45 0100 0101 E 70 46 0100 0110 F 71 47 0100 0111 G
The Digital Revolution in India in the 1990s
Personal computers started getting popular in India towards late 1990s and early 2000s. Offices started getting computers. Digital Typesetting and printing was a popular use case rather than any other computing needs. Even though Unicode existed in theory, Operating Systems then did not provide a method for text input in non-Latin based scripts.
Initially there were no fonts that supported Indian languages. The rendering engines took decades to mature so that they could handle the complex script rendering of Indian languages. Applications like Adobe pagemaker, the popular typesetting tools used in DTP for printing Books, Notices etc. had no proper rendering support for Unicode and Indian languages and had to be handled through many hacks and complex workflows. But the need for typing and printing Indian languages was there.
ASCII Based Indic Language Fonts
The easiest hack to display Indic scripts was to use an ASCII font, but replace the images of English characters with that of Indian languages. There are many such fonts available for different Indian languages. Eg: KrutiDev (Hindi), MLTT-Revathi.
KrutiDev mapping is a non-standard, font-based encoding system widely used in India before Unicode standardization. It uses regular ASCII characters to represent Devanagari, making it incompatible with standard text processing.
This mapping shows how the font relies on visual positioning rather than logical character order—for example, the vowel sign “ि” in KrutiDev appears before the consonant in the stored text. In Kruridev font, while you see हिन्दी, on screen, the actual data stored will be fgUnh as per the table shown here.

This has been a practice in all Indian languages and CDAC has developed several of such non-standard Fonts, as it was the easiest solution possible for displaying Indic scripts. Different ASCII based fonts followed different mappings and it was not possible to read a content created for one font using another font. The character Mapping of MLTT-Revathi is shown below.

Why should you NOT use ASCII based fonts?
- It is impossible to hyphenate your content as hyphenation libraries are written for Unicode.
- It is Impossible to sort your content in ASCII fonts
- If text created in KritiDev or MLTT-Revathi is copy-pasted to another platform where it is not supported, you will be seeing Gibberish like
lkoZtfud izU;kl efUnj Jh egkdkys'oj(Say you copy it to email or Whatsapp) - It is not possible to translate text created in KritiDev or MLTT-Revathi to another language directly, unless you convert it to Unicode first.
- It is not possible to intermix English and Indic scripts in the same document with the same font.
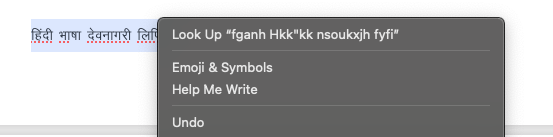
There are tools to convert this gibberish kind of text in one font to Unicode by CDAC and by SMC. But it fails when the document has a mix of non-standard ASCII content and English. The sample below shows how non-standard ASCII font based textmixed with Unicode gets rendered as meaningless character sequences.

Conclusion
The shift from ASCII-based fonts to Unicode has fundamentally improved Indian language computing. While ASCII fonts served immediate typesetting needs in the 1990s, Unicode’s standardized encoding has solved the core issues of text processing, compatibility, and multilingual support.
This article is inspired by the continuous efforts of people like Santhosh Thottingal and Mujeeb Rahman who, through SMC’s Telegram channel and various blogs and vlogs, have been tirelessly educating users about proper text encoding practices. While their technical explanations have helped many individual users transition away from ASCII-based fonts, I felt the need for a comprehensive article that presents this journey to a wider audience. This is my attempt to document this important transition in Indian language computing, hoping it helps more people understand why we must embrace Unicode and leave ASCII-based fonts in the past.