Originally Published in SMC Blog

SMC announces the release of Malayalam Speech Corpus (MSC). It is the repository of curated speech samples collected using MSC web application. Speech samples are selected on the criteria that they have at least 3 positive reviews.
MSC is a project launched by SMC to crowd source Malayalam speech samples from any contributor who can read out sentences and record them as speech samples. The MSC web app has provisions for recording voices and reviewing them. The net upvotes and downvotes received by a speech sample determines is its review score.
The speech data collection is primarily aimed at making an open corpus available for speech technology research. It is necessary to have open and demographically diverse speech datasets to train and develop speech recognizer for Malayalam.The repository contains audio and associated metadata.
Audio and Metadata
Speech files are single channel audio in raw audio format sampled at 48 kHz and encoded with 16 bits per sample. Metadata is published as a list of tab separated values with the following details corresponding to every speech file. It contains an alphanumeric speech id, path of speech file, alphanumeric speaker id, review score, transcript in Malayalam script, Sentence category: proverb, conversation, story or none (indicated by default), Speaker gender: optionally given by user as female, male or other and no response (indicated with default), Speaker age: optionally given by user and no response (indicated with default).
Datasheet
This dataset is accompanied by a datasheet as per the recommendations here. Details on the database creation, curation and maintenance are available in the datasheet.
Data Analysis
The first version of Malayalam Speech Corpus contains 1541 speech samples from 75 contributors amounting to 1:38:16 hours of speech. It has 482 unique sentences, 1400 unique words, 553 unique syllables and 48 unique phonemes.
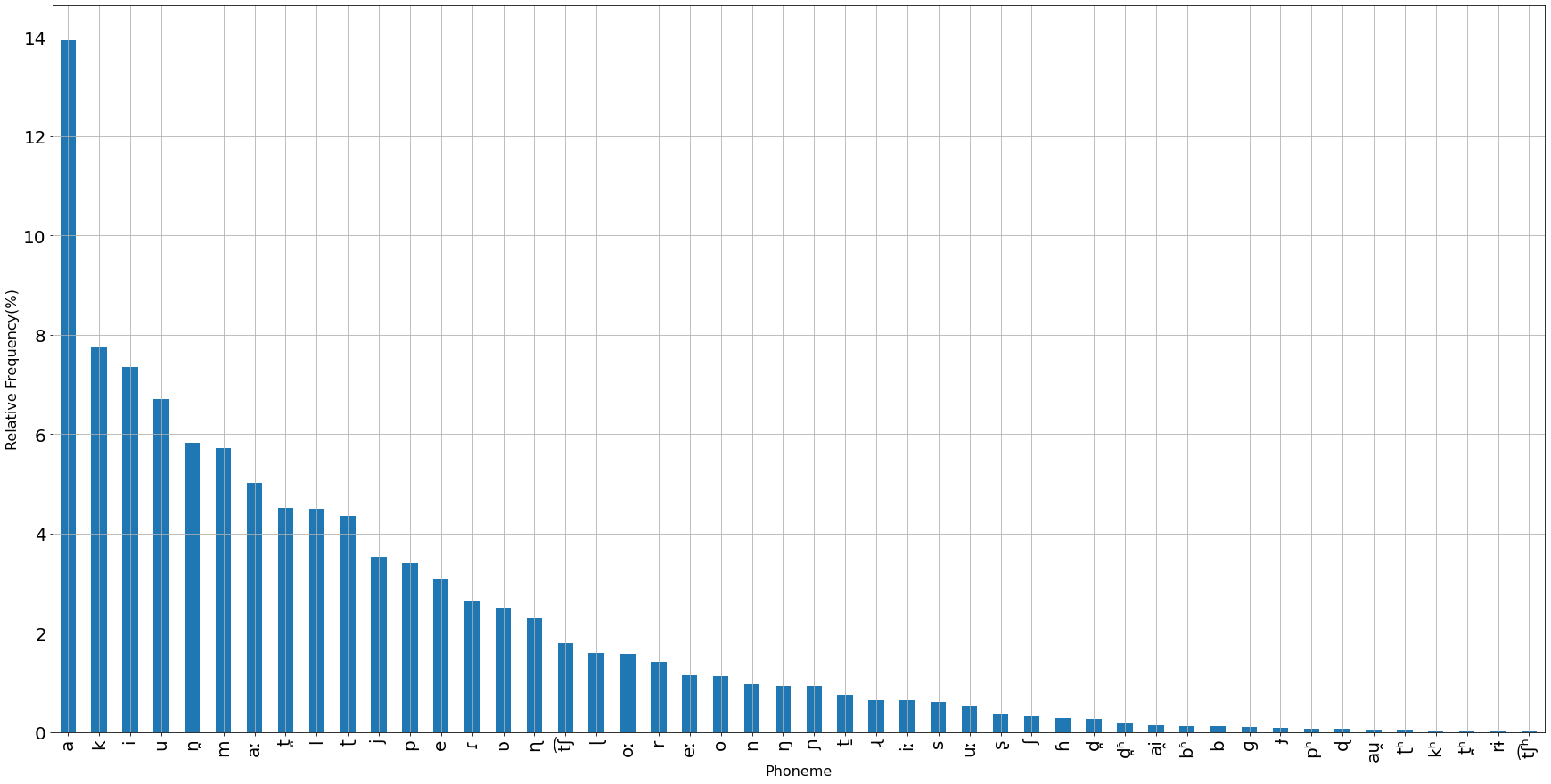
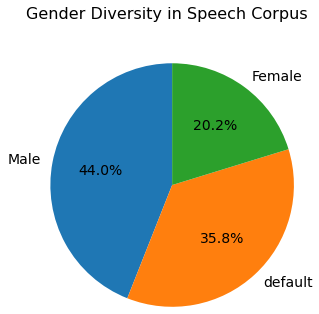
Gender Diversity of Malayalam Speech Corpus (as per the optionally self-declared data from the contributors)
More details on demographic diversity of the corpus and phonetic richness of the dataset are analyzed here.
Usage and License
MSC is licensed under CC-BY-SA 4.0 International License. You can use and redistribute with proper attribution. A typical use case would be to train and test automatic speech recognizer for Malayalam.
Contributing to the corpus
You can contribute your voice by visiting MSC speech collection application. Try to avoid noisy environments while recording. Also you can listen and review the speech recorded by other contributors. Give an upvote if the sample is clearly uttered as the reference sentence and there is no disturbing background noise.