The research carried out as part of my PhD was centred around the linguistic challenges in Malayalam speech recognition. One of the biggest chellenges associated with recognizing speech in morphologically complex languages is centred around how granular should be the text tokens.
Classical ASR with Word tokens
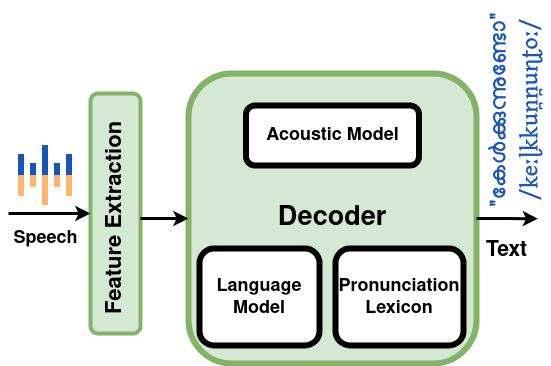
In the classical architecture of Automatic Speech Recognition (ASR) with word tokens, the acoustic model identifies fundamental sound units, the pronunciation lexicon maps sounds to words, and the language model predicts word sequences to convert speech to text. While the acoustic model excels in identifying fundamental sound units from speech’s spectral components, the inclusion of the pronunciation lexicon and language model enhances the overall robustness of the system. The language model can mitigate the impact of imperfect articulation or background noise on spoken words. Even when certain words are not clearly pronounced or are affected by environmental factors, the language model leverages its knowledge of word sequence probabilities to recover and accurately predict the intended spoken words. This compensatory mechanism improves the system’s performance in challenging acoustic conditions.
However, an inevitable trade-off of this architecture is that the overall ASR model, comprised of the acoustic model, pronunciation lexicon, and language model, relies on the information available in the pronunciation dictionary. Consequently, if a word is absent from the pronunciation lexicon, the system faces limitations in providing that specific word at the output. In languages like Malayalam, which are highly morphologically complex, the challenge arises in incorporating all possible compound words and loan words in the pronunciation lexicon. This limitation leads to the identification of spoken words as out-of-vocabulary (OOV), posing a challenge in recovering such words in morphologically complex languages.
Malayalam ASR with sub-Word tokens
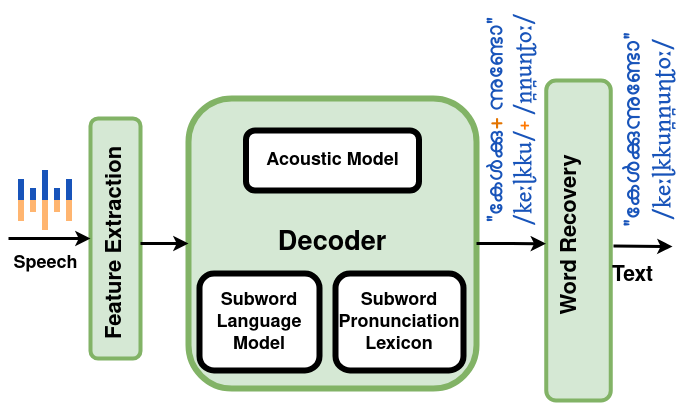
The solution, inspired by successful implementations in other morphologically complex languages, involves leveraging subword tokens instead of complete words, with the flexibility to combine these subwords to form words. The essence of the approach lies in strategically selecting a set of subword tokens to be incorporated into the pronunciation lexicon. The method proposed in my research was to use syllable byte pair encoding (S-BPE) based subword tokenization for Malayalam.
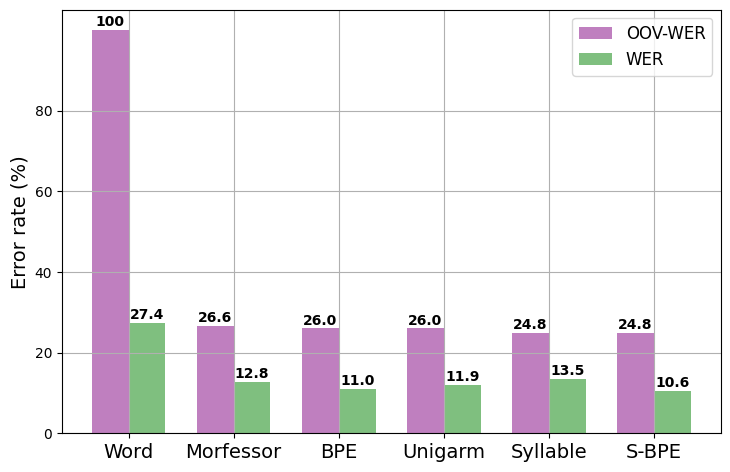
Evaluating the performance of an Automatic Speech Recognition (ASR) model involves assessing the errors it makes when presented with an unseen test speech dataset. In our experiments, we took the evaluation a step further by specifically examining the ASR model’s performance in decoding out-of-vocabulary (OOV) words. The compelling results indicate that across all experiments, lexicons based on subword tokens consistently outperformed word-based baseline model, showcasing lower Word Error Rates (WER) and underscoring the efficacy of subword token approaches in enhancing ASR model accuracy. To have a comprehensive reading on this topic, refer to Improving speech recognition systems for the morphologically complex Malayalam language using subword tokens for language modeling.
Source Code
The model was trained using Kaldi speech recognition toolkit. The training script is available in this repo under Apache 2.0 License.
Applications
Now equipped with our improved ASR model, we have a range of possibilities for its use across different scenarios. Thanks to the open-source community and the tools they’ve developed, we can stand on their shoulders to build and expand further. Vosk toolkit allows you to recognize your speech using an ASR model trained using Kaldi. Vosk provides additional APIs for easy integration into various specific tasks like streaming ASR, live dictation, keyword spotting etc. on light weight devices.
Live Dictation
As a sample application that uses the trained model and leveraging the capabilities of Vosk, a live Malayalam dictation application has been developed. You can simply speak what you want to type, and witness your words form into letters in real-time. In the demo we have used S-BPE based lexicon, with an n-gram order of 4. Pardon my poor UI skills.
The application is licensed under MIT License. Feel free to contribute.
Limitations
Currently the model works well on perfectly articulated speech. This is because majority of the dataset used for training the acoustic model are studio recorded well articulated speech. If we have additional diverse training datasets, it would improve the overall performance of the system.