What is Wav2Vec2-BERT?
Wav2Vec2-BERT is a successor of the popular Wav2Vec2 Model, a pre-trained model for Automatic Speech Recognition (ASR). Wav2Vec2-BERT is a 580M-parameters audio model that has been pre-trained on 4.5M hours of unlabeled audio data covering more than 143 languages. Following the basic architecture of Wav2Vec2, with increased pretraining data and slighly different training objectives, various models (XLSR, XLS-R and MMS) with pretrained checkpoints were released.
Wav2Vec2-BERT pretrained model was introduced in the SeamlessM4T Paper by Meta in August 2023. Every pretrained model in this series is basically a speech representation model trained in a self-supervised manner.
How is Wav2Vec2-BERT different from Whisper?
Wav2Vec2-BERT architecture is much different from the popular Whisper architecture. Whisper is buit on a sequence to sequence transformer architecture. OpenAI released Whisper trained in weakly supervised manner on 680k hours of labelled audio data. Whisper model has a token count of aprroximately 50k. Given the audio with its context, Whisper learns to map them to one of these tokens. The distribution of tokens among different languages/script are highly skewed. The low resorce language characeters are often broken down to multiple tokens, requiring more tokens per word than in a high resource language like English. Let us see how Whisper tokenizes the English word ‘April’ and a Malayalam word ‘ഏപ്രിൽ’ and the corresponding number of tokens in these words.
1
2
3
4
5
6
7
8
from transformers import WhisperTokenizer
tokenizer = WhisperTokenizer.from_pretrained("vrclc/Whisper-small-Malayalam")
tokens_en = tokenizer.tokenize("April")
print("English Tokens", tokens_en)
print("Token Length",len(tokens_en))
tokens_ml = tokenizer.tokenize("ഏപ്രിൽ")
print("Malayalam Tokens", tokens_ml)
print("Token Length",len(tokens_ml))
It results in the following output. As in this case, Whisper has to generate on average more tokens per word, and therefore takes longer to decode.
1
2
3
4
English Tokens ['A', 'pr', 'il']
Token Length 3
Malayalam Tokens ['à´', 'ı', 'à´', 'ª', 'à', 'µ', 'į', 'à´', '°', 'à´', '¿', 'à', 'µ', '½']
Token Length 14
Since Whisper predicts one token at a time, higher the average number of tokens per word, proportionally higher is the decoding time.
Wav2Vec2-BERT in the SeamlessM4T architecture needs explicit finetuing on labelled audiodata for making it usable for an ASR task. The text tokens are custom decided during the finetuning process. Usually the token count is the total number of unique characters in the fine-tuning speech transcripts.
What is the use of external Language Model in ASR?
Wav2Vec2-BERT predicts text tokens in a single pass, making it much faster than Whisper. Wav2Vec2-BERT model is available in Huggingface Transformers and can be finetuned for any low resource ASR task, with a list of custom tokens. During the finetuning process, the model learns to map acoustic features to contextually relevent tokens specific to the language as defined in the custom tokenizer. For low resource ASR tasks the decoder output can be improved by the addition of an external language model by means of a shallow fusion. This technique can be particularly useful for languages with limited amount of annotated audio data for fine-tuning an acoustic model, but has abundant textual data for training a language model.
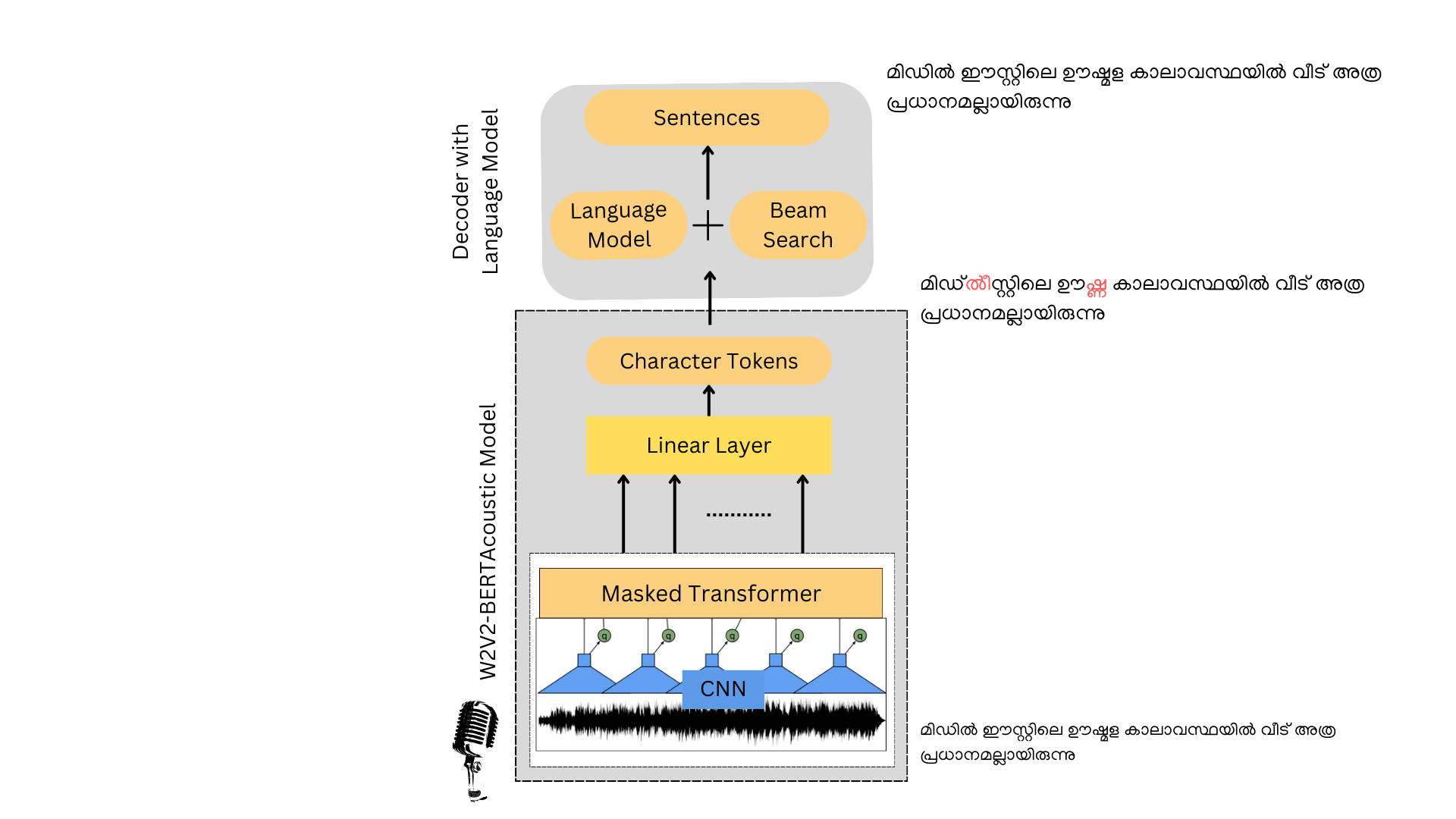
Building an n-gram statistical language model(LM) from text data can be carried out using KenLM library. It can be combined with a fine-tuned Wav2Vec2-BERT ASR model in a similar fashion as described in this popular huggingface blogpost. This blogpost describes how to combine an LM with Wav2Vec2 model. You might need to to choose the appropriate processor when you are tweaking it for the Wav2Vec2-BERT model. It is important that the tokens in the Wav2Vec2-BERT model in tokens.json matches with the alphabet.json file that corresponds to the alphabets in the language model.
This Colab notebook explains how to build a language model using Malayalam text and combine it with Wav2Vec2-BERT Acoustic Model finetuned using Malayalam speech.
Having a language model, helps you recover words even when they are not well articulated in the speech. Sometimes there are character tokens in a language that has the exact same pronunciation. Vowels and vowel signs in Brahmi script languages are an example. The acoustic model learns to map vowels and vowel signs to approximately the same set of acoustic features. So the acoustic model can sometimes confuse between the vowel and vowel signs during decoding. But as per the script and language, vowel signs can follow only the consonants and pure vowels occur only at word beginnings.This linguistic rules get automatically learned, when it has a fused language model. The n-gram language model is a simple statistical model that can predict the probability distribution over the next words, given previous n-1 words.
vrclc/W2V2-BERT-withLM-Malayalam
The Virtual Resource Centre for Lanaguage Computing (VRCLC) at Digital University Kerala has published an ASR model for Malayalam. It has a fine-tuned acoustic model based on the Wav2Vec2-BERT architecture and a statistical trigram language model fused into it by means of shallow fusion. Details on the traning dataset and evaluation results are available in the model card.
Transcribing Speech using Wav2Vec2-BERT+LM model and evaluating performance
Using a shallow fusion language model (LM) with the Wav2Vec2-BERT acoustic model comes with its own pros and cons. The decoder for the
Wav2Vec2-BERT+LMmodel depends on thepyctcdecodelibrary, which works only on CPU and hence the decoding speech might take longer. However there are some workarounds using the batching and pooling features in the Huggingface libraries which will be covered in this blogpost
Before we begin, let us familiarize the steps involved in speech to text conversion
- Extracting features from audio data
- Pass these features to the model to obtain the Logits as the model output
- Decode the logits to character tokens.
We will se how these functions can be implemented using your available hardware CPU and GPU.
1. How to decode an audio using Wav2Vec2-BERT + LM?
Everytime we decode a set of audio, we also evaluate the word error rate. The below script is executed on on Google Colab using only CPU.
You need to install the dependecies.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
# Install dependencies
!pip install datasets transformers evaluate jiwer pyctcdecode kenlm
# Import
from evaluate import load
import torch
from datasets import Audio, load_dataset
from transformers import Wav2Vec2BertForCTC, Wav2Vec2ProcessorWithLM
import time
model_name = "vrclc/W2V2-BERT-withLM-Malayalam" # The Wav2Vec2-BERT+LM Model
totaldata = load_dataset("vrclc/festvox-iiith-ml", split="train") # A Malayalam speech dataset
transcript_column_name = "transcript"
dataset = totaldata.select(range(2)) # Use only two samples of speech
# Defining the Processor
# The processor has a feature extractor and tokenizer.
# When you pass an audio as input, processor_withLM can extract features.
# When you pass the logits produced by the model, processor_withLM can decode it to text tokens
# It depends on the kenlm library to process the language model and pyctcdecode library to generate text tokens
processor_withLM = Wav2Vec2ProcessorWithLM.from_pretrained(model_name) # This is the processor for LM boosted Wav2Vec2-BERT model
# The model is responsible to convert input fetures to logits
model = Wav2Vec2BertForCTC.from_pretrained(model_name) # Defines the Model
sampling_rate = processor_withLM.feature_extractor.sampling_rate
dataset = dataset.cast_column("audio", Audio(sampling_rate=sampling_rate)) # Resample speech to match with the feature extractors sampling rate
# prepare speech data for batch inference. It takes the speech samples array as an entry to the dataset
def map_to_array(batch):
batch["array"] = batch["audio"]["array"]
return batch
dataset = dataset.map(map_to_array)
# Method to map audio array to a prediction of text data.
def map_to_pred1(batch):
batch["reference"] = batch[transcript_column_name] # Read the groundtruth text from dataset for computing WER
input_features = processor_withLM(batch["array"], sampling_rate=sampling_rate, return_tensors="pt") # Extract features using processor_withLM
with torch.no_grad():
logits = model(**input_features).logits # Compute logits from features using the model
transcription = processor_withLM.batch_decode(logits.numpy()).text[0] # Use processor_withLM here to convert logits to text
batch["prediction"] =transcription
return batch
# Pass the audio dataset to the above method to get the prediction
print("Decoding Speech on single CPU")
start_time = time.time()
result1 = dataset.map(map_to_pred1)
end_time = time.time()
print("Time taken: ", end_time - start_time, "seconds")
print("Computing Word Error rate")
wer = load("wer")
WER=(100 * wer.compute(references=result1["reference"], predictions=result1["prediction"]))
print("Reference:", result1["reference"][:])
print("Prediction:", result1["prediction"][:])
print("Word Error Rate (with LM) on single CPU (%):", WER)
This with return the following output:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Fetching 4 files: 100%
4/4 [00:00<00:00, 191.41it/s]
Decoding Speech on single CPU
Map: 100%
2/2 [00:22<00:00, 11.24s/ examples]
Time taken: 31.556140422821045 seconds
Computing Word Error rate
Reference: ['ഇതു നൂറ്റാണ്ടുകൾ പഴക്കം ഉള്ള ഒരു പുരാതന ക്ഷേത്രമാണ്', 'കൊല്ലം എന്ന വാക്കാൽ വിവക്ഷിക്കാവുന്ന ഒന്നിലധികം കാര്യങ്ങളുണ്ട്']
Prediction: ['ഇത് നൂറ്റാണ്ടുകൾ പഴക്കമുള്ള ഒരു പുരാതന ക്ഷേത്രമാണ്', 'കൊല്ലം എന്ന വാക്കാൽ വിവക്ഷിക്കാവുന്ന ഒന്നിലധികം കാര്യങ്ങളുണ്ട്']
Word Error Rate (with LM) on single CPU (%): 23.076923076923077
2. Speeding up the above step using batching and pooling feature in Huggingface library using multiple CPUs
Google Colab has 2 CPUS. Hence we pool two CPUs to batch decode as shown in the script here:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
# Install dependencies
!pip install datasets transformers evaluate jiwer pyctcdecode kenlm
# Import
from evaluate import load
import torch
from datasets import Audio, load_dataset
from transformers import Wav2Vec2BertForCTC, Wav2Vec2ProcessorWithLM
import time
from multiprocessing import get_context # For CPU pooling
model_name = "vrclc/W2V2-BERT-withLM-Malayalam" # The Wav2Vec2-BERT+LM Model
totaldata = load_dataset("vrclc/festvox-iiith-ml", split="train") # A Malayalam speech dataset
transcript_column_name = "transcript"
dataset = totaldata.select(range(2)) # Use only two samples of speech
# Defining the Processor
# The processor has a feature extractor and tokenizer.
# When you pass an audio as input, processor_withLM can extract features.
# When you pass the logits produced by the model, processor_withLM can decode it to text tokens
# It depends on the kenlm library to process the language model and pyctcdecode library to generate text tokens
processor_withLM = Wav2Vec2ProcessorWithLM.from_pretrained(model_name) # This is the processor for LM boosted Wav2Vec2-BERT model
# The model is responsible to convert input fetures to logits
model = Wav2Vec2BertForCTC.from_pretrained(model_name) # Defines the Model
sampling_rate = processor_withLM.feature_extractor.sampling_rate
dataset = dataset.cast_column("audio", Audio(sampling_rate=sampling_rate)) # Resample speech to match with the feature extractors sampling rate
# prepare speech data for batch inference. It takes the speech samples array as an entry to the dataset
def map_to_array(batch):
batch["array"] = batch["audio"]["array"]
return batch
dataset = dataset.map(map_to_array)
# Method to map audio array to a prediction of text data.
def map_to_pred2(batch, pool):
batch["reference"] = batch[transcript_column_name] # Read the groundtruth text from dataset for computing WER
input_features = processor_withLM(batch["array"], sampling_rate=sampling_rate, return_tensors="pt") # Extract features using processor_withLM
with torch.no_grad():
logits = model(**input_features).logits # Compute logits from features using the model
transcription = processor_withLM.batch_decode(logits.numpy(),pool).text # Use processor_withLM here to convert logits to text
batch["prediction"] =transcription
return batch
# Pass the audio dataset to the above method to get the prediction.
print("Decoding Speech on two CPU")
start_time = time.time()
with get_context("fork").Pool(processes=2) as pool:
result2 = dataset.map(
map_to_pred2, batched=True, batch_size=2, fn_kwargs={"pool": pool}
)
end_time = time.time()
print("Time taken: ", end_time - start_time, "seconds")
print("Computing Word Error rate")
wer = load("wer")
WER=(100 * wer.compute(references=result2["reference"], predictions=result2["prediction"]))
print("Reference:", result2["reference"][:])
print("Prediction:", result2["prediction"][:])
print("Word Error Rate (with LM) on two CPUs (%):", WER)
It gives the following output.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Fetching 4 files: 100%
4/4 [00:00<00:00, 103.48it/s]
Decoding Speech on two CPU
Map: 100%
2/2 [00:19<00:00, 9.50s/ examples]
Time taken: 19.50375485420227 seconds
Computing Word Error rate
Reference: ['ഇതു നൂറ്റാണ്ടുകൾ പഴക്കം ഉള്ള ഒരു പുരാതന ക്ഷേത്രമാണ്', 'കൊല്ലം എന്ന വാക്കാൽ വിവക്ഷിക്കാവുന്ന ഒന്നിലധികം കാര്യങ്ങളുണ്ട്']
Prediction: ['ഇത് നൂറ്റാണ്ടുകൾ പഴക്കമുള്ള ഒരു പുരാതന ക്ഷേത്രമാണ്', 'കൊല്ലം എന്ന വാക്കാൽ വിവക്ഷിക്കാവുന്ന ഒന്നിലധികം കാര്യങ്ങളുണ്ട്']
Word Error Rate (with LM) on two CPUs (%): 23.076923076923077
3. Using GPU to get the logits from the Model
Here we use GPU to convert the speech features to corresponding logits. These logits in GPU RAM can not be processed on CPU for converting to text. Hence they has to be passed to the CPU.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
# Install dependencies
!pip install datasets transformers evaluate jiwer pyctcdecode kenlm
# Import
from evaluate import load
import torch
from datasets import Audio, load_dataset
from transformers import Wav2Vec2BertForCTC, Wav2Vec2ProcessorWithLM
import time
from multiprocessing import get_context # For CPU pooling
model_name = "vrclc/W2V2-BERT-withLM-Malayalam" # The Wav2Vec2-BERT+LM Model
totaldata = load_dataset("vrclc/festvox-iiith-ml", split="train") # A Malayalam speech dataset
transcript_column_name = "transcript"
dataset = totaldata.select(range(2)) # Use only two samples of speech
# The processor has a feature extractor and tokenizer.
# When you pass an audio as input, processor_withLM can extract features.
# When you pass the logits produced by the model, processor_withLM can decode it to text tokens
# It depends on the kenlm library to process the language model and pyctcdecode library to generate text tokens
processor_withLM = Wav2Vec2ProcessorWithLM.from_pretrained(model_name) # This is the processor for LM boosted Wav2Vec2-BERT model
device ="cuda"
# The model is responsible to convert input fetures to logits
model = Wav2Vec2BertForCTC.from_pretrained(model_name).to(device) # Defines the Model. It can decode features to logits using GPU
sampling_rate = processor_withLM.feature_extractor.sampling_rate
dataset = dataset.cast_column("audio", Audio(sampling_rate=sampling_rate)) # Resample speech to match with the feature extractors sampling rate
# prepare speech data for batch inference. It takes the speech samples array as an entry to the dataset
def map_to_array(batch):
batch["array"] = batch["audio"]["array"]
return batch
dataset = dataset.map(map_to_array)
# Method to map audio array to a prediction of text data.
def map_to_pred3(batch, pool):
batch["reference"] = batch[transcript_column_name]
input_features = processor_withLM(batch["array"], sampling_rate=sampling_rate, padding=True, return_tensors="pt")
with torch.no_grad():
logits = model(**input_features.to(device)).logits
# print(logits.shape)
prediction = processor_withLM.batch_decode(logits.cpu().numpy(), pool).text
batch["prediction"] = prediction
return batch
# Pass the audio dataset to the above method to get the prediction.
print("Decoding Speech on two CPU, and 1 GPU")
start_time = time.time()
with get_context("fork").Pool(processes=2) as pool:
result3 = dataset.map(
map_to_pred3, batched=True, batch_size=2, fn_kwargs={"pool": pool}
)
end_time = time.time()
print("Time taken: ", end_time - start_time, "seconds")
print("Computing Word Error rate")
wer = load("wer")
WER=(100 * wer.compute(references=result3["reference"], predictions=result3["prediction"]))
print("Reference:", result3["reference"][:])
print("Prediction:", result3["prediction"][:])
print("Word Error Rate (with LM) on two CPU and 1 GPU(%):", WER)
It gives the following output:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Fetching 4 files: 100%
4/4 [00:00<00:00, 93.29it/s]
Decoding Speech on two CPU, and 1 GPU
Map: 100%
2/2 [00:00<00:00, 3.68 examples/s]
Time taken: 0.8980085849761963 seconds
Computing Word Error rate
Reference: ['ഇതു നൂറ്റാണ്ടുകൾ പഴക്കം ഉള്ള ഒരു പുരാതന ക്ഷേത്രമാണ്', 'കൊല്ലം എന്ന വാക്കാൽ വിവക്ഷിക്കാവുന്ന ഒന്നിലധികം കാര്യങ്ങളുണ്ട്']
Prediction: ['ഇത് നൂറ്റാണ്ടുകൾ പഴക്കമുള്ള ഒരു പുരാതന ക്ഷേത്രമാണ്', 'കൊല്ലം എന്ന വാക്കാൽ വിവക്ഷിക്കാവുന്ന ഒന്നിലധികം കാര്യങ്ങളുണ്ട്']
Word Error Rate (with LM) on two CPU and 1 GPU(%): 23.076923076923077
4. Can I just skip making use of the LM?
Yes. Since it is a shallow fusion model, the LM is not tightly bound the acoustic model. You can very well skip using the LM.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
# Install dependencies
!pip install datasets transformers evaluate jiwer pyctcdecode kenlm
# Import
from evaluate import load
import torch
from datasets import Audio, load_dataset
from transformers import Wav2Vec2BertForCTC, Wav2Vec2BertProcessor
import time
model_name = "vrclc/W2V2-BERT-withLM-Malayalam" # The Wav2Vec2-BERT+LM Model
totaldata = load_dataset("vrclc/festvox-iiith-ml", split="train") # A Malayalam speech dataset
transcript_column_name = "transcript"
dataset = totaldata.select(range(2)) # Use only two samples of speech
# The processor has a feature extractor and tokenizer.
# When you pass an audio as input, processor_withLM can extract features.
# When you pass the logits produced by the model, processor_withLM can decode it to text tokens
# It depends on the kenlm library to process the language model and pyctcdecode library to generate text tokens
processor = Wav2Vec2BertProcessor.from_pretrained(model_name) # This is the processor for LM boosted Wav2Vec2-BERT model
device ="cuda"
# The model is responsible to convert input fetures to logits
model = Wav2Vec2BertForCTC.from_pretrained(model_name).to(device) # Defines the Model. It can decode features to logits using GPU
sampling_rate = processor.feature_extractor.sampling_rate
dataset = dataset.cast_column("audio", Audio(sampling_rate=sampling_rate)) # Resample speech to match with the feature extractors sampling rate
# prepare speech data for batch inference. It takes the speech samples array as an entry to the dataset
def map_to_array(batch):
batch["array"] = batch["audio"]["array"]
return batch
dataset = dataset.map(map_to_array)
# Method to map audio array to a prediction of text data.
def map_to_pred4(batch):
batch["reference"] = batch[transcript_column_name]
input_features = processor(batch["array"], sampling_rate=sampling_rate, return_tensors="pt").input_features
logits = model(input_features.to(device)).logits
with torch.no_grad():
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)[0]
batch["prediction"] =transcription
return batch
# Pass the audio dataset to the above method to get the prediction.
print("Decoding Speech on 1 GPU without LM")
import time
start_time = time.time()
result4 = dataset.map(map_to_pred4)
end_time = time.time()
print("Time taken: ", end_time - start_time, "seconds")
print("Computing Word Error rate")
wer = load("wer")
WER=(100 * wer.compute(references=result4["reference"], predictions=result4["prediction"]))
print("Reference:", result4["reference"][:])
print("Prediction:", result4["prediction"][:])
print("Word Error Rate (without LM) on 1 GPU(%):", WER)
It gives the output
1
2
3
4
5
6
7
8
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Decoding Speech on 1 GPU without LM
Time taken: 7.927062749862671 seconds
Computing Word Error rate
Reference: ['ഇതു നൂറ്റാണ്ടുകൾ പഴക്കം ഉള്ള ഒരു പുരാതന ക്ഷേത്രമാണ്', 'കൊല്ലം എന്ന വാക്കാൽ വിവക്ഷിക്കാവുന്ന ഒന്നിലധികം കാര്യങ്ങളുണ്ട്']
Prediction: ['ഇത് നൂറ്റാണ്ടുകൾ പഴക്കമുള്ള ഒരു പുരാതന ക്ഷേത്രമാണ്', 'കൊല്ലം എന്ന വാക്കാൽ വിവക്ഷിക്കാവുന്ന ഒന്നിലധികം കാര്യങ്ങളുണ്ട്']
Word Error Rate (without LM) on 1 GPU(%): 23.076923076923077