This is a two part article. The first part will cover how the normalization routine in the popular ASR engine Whisper, removes essential characters like vowel signs in Indian languages while evaluating the performance. The second part (yet to be written) will cover various existing libraries and the approaches needed to perform proper normalization in Indian languages.
Text Normalization
Text Normalization in natural language processing (NLP) refers to the conversion of different written forms of text to one standardised form. The definition of the standard form depends largely on the problem at hand.
For the textual NLP models, the text is the data from which a hidden pattern is learnt. When there is multiple valid ways to represent the same text (eg: are not and are’nt), converting them to one common form, (eg: are not), reduces the information spread, and the model can learn the patterns easily. The extent of normalization routine depends on the use case. For example the (upper or lower) case information may be very relevant in tasks like named entity recognition in English.
Text Normalization for Speech Tasks
In this article I will focus on the specific use case of applying normalization in the context of speech tasks like automatic speech recognition (ASR) and text to speech (TTS). While training the acoustic model in English ASR and TTS systems, it is a popular practice to normalize the speech transcripts. The purpose here is to make the best match of text with the audio. The steps in it include:
- conversion to a common case (upper or lower)
- removal of punctuations
- converting numbers into words
- text canonicalization (eg: tumor = tumour, for UK and US English spellings)
- expansion of abbreviations (eg: Prof. = professor) and contractions (eg: are’nt = are not)
For an ASR system, it means the output would be normalized too. We would need additional modules for performing inverse text normalization. This also means the TTS systems would need a pre-processing module for normalizing the text before synthesis.
Evaluating ASR systems: The case of Whisper multilingual normalizer
The Whisper approach of ASR system, avoids the usage of normalization of training data. It uses a weakly supervised pretraining approach with 680k hours of multilingual (117k hours of non-English languages) annotated speech data. Annotations are speech transcripts with casing and punctuations retained as such. Whisper English ASR output would give you cased text with punctuations which is much appealing for a human user. This worked, because of the sheer size of the training data.
But how would you evaluate an ASR system? ASR systems are evaluated using a parameter called word error rate (WER). Let as take an example:
Ground Truth: I am Kavya. How are you?
ASR Prediction: I'm Kavya. how old are you?
How does each word in the ground truth compares with the predicted words? Some words are predicted correctly, while some words are substituted or deleted. Sometimes the prediction contains words not present in the ground truth, and it is considered as an insertion.
$$I \rightarrow I’m\ (Substitution,S)$$ $$am \rightarrow \phi\ (Deletion,D)$$ $$Kavya. \rightarrow Kavya.\ (Correct,C)$$ $$How \rightarrow how\ (Substitution, S)$$ $$\phi \rightarrow old\ (Insertion,I)$$ $$are \rightarrow are\ (Correct,C)$$ $$you? \rightarrow you?\ (Correct,C)$$
$$WER = \frac{I+D+S}{Total\ words\ in\ Ground\ Truth} $$
$$WER = \frac{1+1+2}{6} = \frac{4}{6} = 0.667$$
The WER in percentage will be 66.7%. In general lower the word error rate, better the ASR model is. However, In the above example, if both the ground truth and the ASR prediction were normalized before evaluation, as shown next:
Normalized Ground Truth: i am kavya how are you
Normalized ASR Prediction : i am kavya how old are you
$$i \rightarrow i\ (Correct,C)$$ $$am \rightarrow am\ (Correct,C)$$ $$kavya \rightarrow kavya\ (Correct,C)$$ $$how \rightarrow how\ (Correct,C)$$ $$\phi \rightarrow old\ (Insertion,C)$$ $$are \rightarrow are\ (Correct,C)$$ $$you \rightarrow you\ (Correct,C)$$
$$WER = \frac{1+0+0}{6} = \frac{1}{6} = 0.167$$
The WER has dropped down to 16.7%. It shows that the normalization has removed unnecessary penaly on the model output. Hence the Whisper paper has introduced a rigorous normalization routine before evaluating WER.
Quoting from the Whisper Paper,
English normalization:
Since Whisper may output any UTF-8 string rather than a restricted set of graphemes, the rules for text standardization need to be more intricate and comprehensive than those defined on e.g. ASCII characters. We perform the following steps to normalize English texts in different styles into a standardized form, which is a best-effort attempt to penalize only when a word error is caused by actually mistranscribing a word, and not by formatting or punctuation differences.
- Remove any phrases between matching brackets ([, ]).
- Remove any phrases between matching parentheses ((, )).
- Remove any of the following words: hmm, mm, mhm, mmm, uh, um
- Remove whitespace characters that comes before an apostrophe ’
- Convert standard or informal contracted forms of English into the original form.
- Remove commas (,) between digits
- Remove periods (.) not followed by numbers
- Remove symbols as well as diacritics from the text, where symbols are the characters with the Unicode category starting with M, S, or P, except period, percent, and currency symbols that may be detected in the next step.
- Detect any numeric expressions of numbers and currencies and replace with a form using Arabic numbers, e.g. “Ten thousand dollars” → “$10000”.
- Convert British spellings into American spellings.
- Remove remaining symbols that are not part of any numeric expressions.
- Replace any successive whitespace characters with a space.
However implementing the normalization routine with same rigour on all languages would require strong linguistic knowhow. So the Whisper paper sticks to a simple set of common rules for all other languages:
Quoting from the Whisper Paper,
Non-English Normalization:
A different, language-specific set of transformations would be needed to equivalently normalize non-English text, but due to our lack of linguistic knowledge to build such normalizers for all languages, we resort to the following basic standardization for non-English text:
- Remove any phrases between matching brackets ([, ]).
- Remove any phrases between matching parentheses ((, )).
- Replace any markers, symbols, and punctuation characters with a space, i.e. when the Unicode category of each character in the NFKC-normalized string starts with M, S, or P.
- make the text lowercase.
- replace any successive whitespace characters with a space.
Additionally, we put a space between every letter for the languages that do not use spaces to separate words, namely Chinese, Japanese, Thai, Lao, and Burmese, effectively measuring the character error rate instead.
We note that the above is an imperfect solution, and it will sometimes produce unintended and unexpected outputs. We do not claim that the text format resulting from the above is more “correct” in any measure. Rather, the procedures above are designed to better distinguish between innocuous differences in wording and genuine mistranscriptions. Python code for the standardization procedures above is available as part of our code and model release to facilitate future iterations and improvements on text standardization.
A deep dive into the problematic step in Whisper normalization for non-English Languages
Even though the Whisper team does not claim any sort of “correctness” in the above implementation, let us take a closer look into the normalization step 3. It intends to remove punctuation characters and diacritic marks. What happens when we perform this operation for Indian languages?
Let us first see how the WER evaluation occurs on unnormalized text in Malayalam:
1
2
3
4
5
6
7
8
from evaluate import load
evaluation_metric = load("wer")
groundtruths =[ "റബ്ബർ എന്ന വാക്കാൽ വിവക്ഷിക്കാവുന്ന ഒന്നിലധികം കാര്യങ്ങളുണ്ട്"]
predictions = ["റബ്ബർ എന്ന വാക്കാൽ വിവക്ഷിക്കാവുന്ന ഒന്നിലകം കാര്യങ്ങളുണ്ട്"]
print("Groundtruth:",groundtruths[0])
print("Prediction:",predictions[0])
WER = 100 * evaluation_metric.compute(references=groundtruths,predictions=predictions)
print("Regular Word Error Rate (%):", WER)
It will generate the output:
Groundtruth: റബ്ബർ എന്ന വാക്കാൽ വിവക്ഷിക്കാവുന്ന ഒന്നിലധികം കാര്യങ്ങളുണ്ട്
Prediction: റബ്ബർ എന്ന വാക്കാൽ വിവക്ഷിക്കാവുന്ന ഒന്നിലകം കാര്യങ്ങളുണ്ട്
Regular Word Error Rate (%): 16.666666666666664
Everything is well and good so far. Now what if we perform Whisper normalization before the evaluation of WER?
9
10
11
12
13
14
15
16
17
18
from transformers.models.whisper.english_normalizer import BasicTextNormalizer
normalizer = BasicTextNormalizer()
# compute normalised WER
normalized_groundtruths = [normalizer(label) for label in groundtruths]
normalized_predictions = [normalizer(pred) for pred in predictions]
print("Normalized Groundtruth:",normalized_groundtruths[0])
print("Normalized Prediction:",normalized_predictions[0])
normalized_WER = 100 * evaluation_metric.compute(references=normalized_groundtruths,predictions=normalized_predictions)
print("Normalized Word Error Rate (%):", normalized_WER)
It will generate the output:
Normalized Groundtruth: റബ ബർ എന ന വ ക ക ൽ വ വക ഷ ക ക വ ന ന ഒന ന ലധ ക ക ര യങ ങള ണ ട
Normalized Prediction: റബ ബർ എന ന വ ക ക ൽ വ വക ഷ ക ക വ ന ന ഒന ന ലക ക ര യങ ങള ണ ട
Normalized Word Error Rate (%): 7.6923076923076925
What if Hindi text is used instead of Malayalam?
Running the above code on Hindi text will generate the output:
Groundtruth: सामाजिक विज्ञान और दर्शन
Prediction: सामाजिक विज्ञान और दर्श
Regular Word Error Rate (%): 25.0
Normalized Groundtruth: स म ज क व ज ञ न और दर शन
Normalized Prediction: स म ज क व ज ञ न और दर श
Normalized Word Error Rate (%): 9.090909090909092
From the discussion so far, two observations can be made:
- The WER has reduced from 16.6% to 7.69% (Malayalam) and 25% to 9.09% (Hindi)
- The Normalization has removed all vowel signs and the Virama sign from the Indian language text and inserted space instead, effectively rendering a meaningless character sequence.
What is happening here and Why?
The normalization step for non-English languages removes all characters that fall in the unicode category string starts with M, S, or P. All the vowel signs and the virama signs in the Brahmi family of scripts Devanagari, Malayalam, Tamil, Telugu, Bengali etc. belong to the Unicode category of ‘Mark’ which starts with M. The Whisper normalization script removes these important characters.
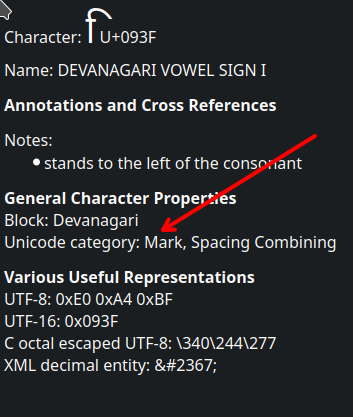
Does this issue affect Europen languages like Finnish or Swedish?
Diacritic marks are important characters and they should not be removed as part of normalization routine in many languages. Let us see how Whisper normalization works on a Finnish sample text.
Groundtruth: Perussuomalaisten eduskuntaryhmä erotti Timo Vornasen
Prediction: Perussuomalaisten eduskuntaryhmä erotti Timo Vornasen
Regular Word Error Rate (%): 20.0
Normalized Groundtruth: perussuomalaisten eduskuntaryhmä erotti timo vornasen
Normalized Prediction: perussuomalaisten eduskuntaryhmä erotti timo vornasen
Normalized Word Error Rate (%): 0.0
Whisper normalization has not only retained the word ’eduskuntaryhmä’ with diacritics, but also brought down the WER. It works as intended. The trick here is the NFKC step.
What is NFKC (Normalization Form Compatibility Composition)?
There are multiple unicode character sequences that result in the same visual form. In the above sample ä in the Ground truth is composed of two unicode characters: a (U+0061)and ̈ (Combining Diaerisis U+0308). However the ä in the Prediction is a single unicode character U+00E4. This difference is the reason for WER when computed without normalization.
In Whisper normalization, first NFKC is performed. It converts both ä (U+0061,U+0308) and ä (U+00E4) into the composed form ä (U+00E4). This composed form belongs to the unicode category of ‘Letter’ and not ‘Mark’. Hence this character is retained as such after normalization.

It needs further investigation to check if there are any important diacritics that are removed in European languages by Whisper normalization.
The Implications of Whisper Normalization
During the Whisper fine-tuning event hosted by Hugging Face in December 2022, researchers and practitioners worldwide collaborated to enhance the basic Whisper model using target language datasets, aiming to elevate the speech recognition system for all languages.
The winning models in various Indian languages showcased an unbelievably low word error rate (WER), with figures like 8% for Tamil, 11.49% for Malayalam, 10.05% for Hindi, and 11.11% for Bengali. The leaderboard’s promising results initially led the speech research community to believe we have achieved the peak of possibilities.
However, the above discussion reveals that the remarkably low WER wasn’t attributed to the impressive pretraining or fine-tuning efforts of Whisper but rather to a glitch in the evaluation suite.
In a blog post, Benjamin Marie has pointed out that the Whisper is claiming SOTA on many tasks by comparing the uncomparable. None of the previous work had used the Whisper kind of normalization. Still all comparisons with prior works are based on the normalized WER reported in Whisper paper.
Whisper was released in September 2022. However it is surprising that no one has specifically noted or documemented this serious error in the normalization of Indian languages. There has been other analysis emphasising the need for normalizer in ASR benchmarking, but none has touched upon this specific issue of vanishing vowels in Indian languages.
Edited on 8 August 2024: Recently I came across this blogpost by Ross O’Connell that specifically calls out this issue with examples from Tamil and generalized to all Brahmic script languages. It was published in May 19, 2023. But I had missed it.
Further the same normalization routine is followed by ASR models like AssemblyAI Conformer-1 model and Meta’s MMS, perpetuating this issue further.
Text Normalization for Indian Languages
Indian language text in the web are largely erroneus and require a proper clean up routine, before text normalization. A detailed discussion on this and existing approaches for Indian language text normalization will be the content of the part 2 of this article.
Thanks for Reading. Part 2 coming up soon