I wrote this article for submission to a popular science writing competition by the Department of Science and Technology. Here is my research story, which did not make to grab the award. The story is based on our research on the morphological richness of Malayalam language.
How many words are there in your language? How many of them do you know? Can you find all those words in a dictionary? You never worry about these things while communicating with people around you in daily life. As speech technology researchers, we had to probe into this, while trying to make computers recognize human speech in our native language, Malayalam. Speech recognizer is basically a computer application that can convert spoken language into textual form. The problem before us was how many words we will have to teach computers, so that they can do a close to human performance to recognize speech in Malayalam.
Every language has a set of words. You can look up those words in a dictionary and find its meaning. The word list is not fixed, it grows forever. In the due course some words become obsolete. In the past few months we all know how every Indian language has grown its vocabulary with ‘COVID’ and many related words.

By word, we mean a group of letters that has a meaning on its own. They are typically shown with a space on either side, when written or printed. Many languages produce words by fusing together existing words. But some languages do this so heavily that the fusion can span over many words, finally forming a single longer word.
This concept is more or less similar to forming larger and larger numbers using just ten digits from zero to nine. As a child you learn the trick of forming a two-digit or three-digit number at school. Then you learn to perceive any large number no matter how many digits are there in it. You don’t have to byheart every possible number so that you can use it at some point in your life. But the trick is, you understand the pattern and the concept of number formation.
The mechanism of word formation
Consider a simple English sentence, ‘I am here’. How would you translate that to an Indian language? It is translated to Hindi as a three word sentence, ‘main yahaan hoon’. But a native Malayalam speaker translates it as a single word sentence ‘njanivideyund’. It is a very common statement in Malayalam which has three words fused together into one single word.
Word fusion is not a property unique to Malayalam. It can happen in many ways in different languages. The English adjective word ‘predictable’ can get inflected by a grammatical indicator to form the noun ‘predictability’. The singular word ‘leaf’ can get inflected by the plural indicator ‘s’ to form the word ‘leaves’. The word ‘ladki’ in Hindi has its plural ‘ladkiyaan’ which is inflected form of its singular counterpart. The fusion of grammatical indicators to root words is termed as inflection. The Hindi compound word ‘pustakalay’ (library) is formed by combining the root words ‘pustak’(book) and ‘aalay’(house). The formation of long compound words by gluing sequences of root words is termed as agglutination. These are in fact the sandhi and samas rules we learn in grammar classes. The degree to which a language allows inflections, agglutinations and their combinations indicate how complex the words structure of that language can become. This property can be described as the morphological richness of the language.
Table 1 shows a few examples of how Malayalam allows morphologically complex words by inflections and agglutinations. This process is associated with pronunciation changes at the word boundaries as in the English word ‘leaf’ becoming ‘leaves (leaf+s)’ after inflection. As speech technology researchers, pronunciation changes matter a lot to us.
| English | Hindi | Malayalam |
|---|---|---|
| Who will bell the cat? | billee ko ghantee kaun dega? | poochaykkaaru manikettum? |
| I don’t know | mujhe nahin pata | eniykkariyilla |
| to be or not to be is the question | hona ya na hona hai prashn | veno vendayo ennathanu chodyam |
Table 1: Sentences of same meaning in three languages. Malayalam sentences have agglutinated and inflected wordforms and their repetitions are rare in a body of text.
Measuring morphological richness
A baby growing up listening to Malayalam conversations, catches up not just the simple words, but this technique of word fusion as well. They start to produce and recognize compound Malayalam words. Their brain gets trained to handle pronunciation changes at word boundaries. Morphological richness does not make a language better or poor in any sense. It is just a feature of the language. Human brains can very well handle any such feature. But our computers are not yet as good as human brains. Inorder to devise strategies to make our computers and smartphones recognize Malayalam, we wanted to know where Malayalam stands in terms of its morphological richness.
Our method to measure morphological richness was to count the number of unique words in a large collection of Malayalam text. If a language is morphologically rich it will have a large number of unique words which are fused from smaller words. We examined all the Malayalam Wikipedia articles. It contained more than 80 lakh words in total. Surprisingly, of these words, 12 lakh were unique! That is a really huge count. We tabulated and plotted graphs indicating the growth of unique word counts with respect to the total word count. This is a parameter known as type-token growth rate. We compared the our results with the reported values of various computational linguistic parameters including type-token growth rate, type-token ratio and moving average type token ratio from other studies on different Indian and foreign languages. Every comparison revealed Malayalam has higher degrees of morphological richness. In the following section we shall see how does morphological richness impact speech recognition systems.
Morphology aware speech recognition
We humans use our ears to hear the sounds and process it in our brain to match it with words we know in our language. To make a computer do that, we have to familiarize computers with all phonemes. Phonemes are the smallest distinguishable sound in a language. In a speech recognizer, there should be a mathematical system that relates speech signals and phonemes in a language. It is called an acoustic model.
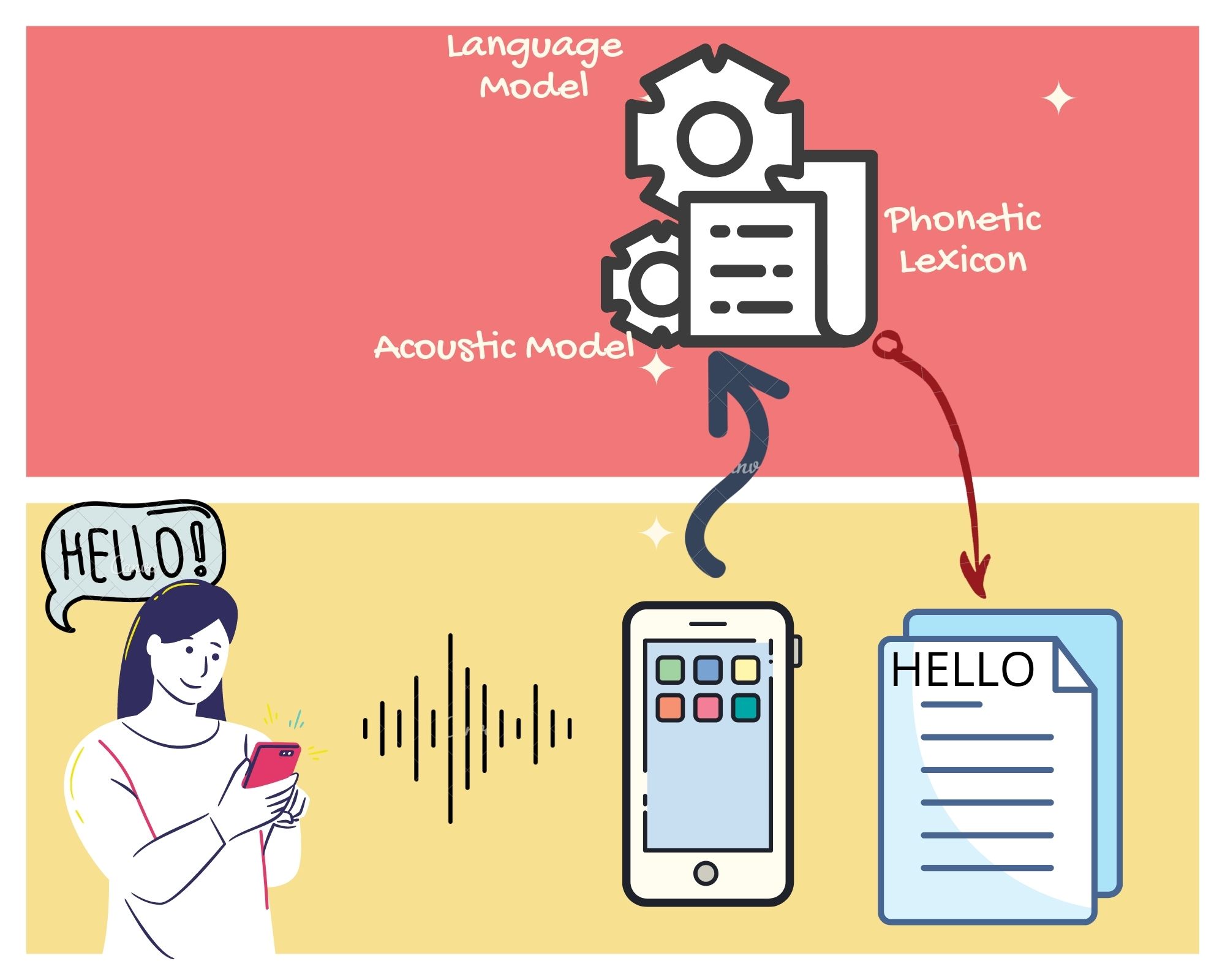
Speech recognition in action: A device uses an acoustic model, a language model and a phonetic lexicon to convert spoken language to textual form
A system that learns the words in a language and their chances of being spoken in the context of some other word sequence is called a language model. The machine also needs a list of all words that we want it to recognize. This list is a dictionary that describes how each word is to be pronounced, as a sequence of phonemes. Technically that dictionary is called a phonetic lexicon. The popular English phonetic lexicon, CMUDict, prepared by Carnegie Mellon University contains less than 1.5 lakh words. That is far less than the number of unique words we found in Malayalam Wikipedia articles. So how large would be the phonetic lexicon for Malayalam? By theory there is no limit to which Malayalam words can undergo inflections and agglutinations. This leads to a possibility of infinite vocabulary. But practically it is not easy to have an infinitely long phonetic lexicon. So what could be an alternative?
If we can we incorporate the linguistic trick of word fusion into computers, it would equip them to have a better language model. It enables them to create a phonetic lexicon as and when required. This is what we are currently working on, the morphology aware speech recognition system. This research direction is relevant for other morphologically rich Indian languages as well. It will eventually enable you to get automatic transcription while watching your favourite videos, type text using voice and even talk with your digital assistant, all in your native language. We hope to give our computers and smartphones a bit more humane touch by making them recognize our native spoken languages.