Edit (September 20,2022): A detailed report on this is now available as a journal article
What is a Phonetic analyser?
‘Phoneme’ is the fundamental unit in the the speech system of the language. ‘Grapheme’ is the fundamental unit in the writing system. From one or more graphemes a phoneme can be synthesized. A phonetic analyser analyses the written form of the text to give the phonetic characteristics of the grapheme sequence.
Understanding the phonetic characteristics of a word is helpful in many computational linguistic problems. For instance, translating a word into its phonetic representation is needed in the synthesis of a text to speech (TTS) system. The phonetic representation is helpful to transliterate the word to a different script. It will be useful if the phonetic representation can be converted back to the grapheme sequence - requirement for speech synthesis systems. A finite state transducer (FST) helps us to achieve this.
Finite State Transducers consists of a finite number of states which are linked by transitions labeled with an input/output pair. The FST starts out in a designated start state and jumps to different states depending on the input, while producing output according to its transition table.
Grapheme to Phoneme (g2p) mapping
FSTs can be used for mapping graphemes to phonemes and the reverse. Grapheme to phoneme (g2p) correspondence may not be always one-to-one. If the orthography (writing system) of a language is phonemic, then its g2p conversion would have been straightforward. Malayalam, like other indic languages has mostly phonemic orthography unlike English which is non-phonemic.
The g2p mapping of Malayalam requires certain contextual rules to be applied to handle schwa addition at beginning/end/middle of words depending on the presence of chillus and virama, phonetic changes that occur in the context of certain sequence of consonants, contextual nasalisation etc. It is usually required that the process is bidirectional. Ie., the grapheme to phoneme correspondence (GPC) system should be able to retrieve the orthographic representation of the language in the native script from the phonetic sequence.
The phonetic representation currently used is the International Phonetic Alphabets (IPA). Along with IPA, the articulatory features of the consonants are provided. I have used Thunchath Ezhuthachan Malayalam University’s phonetic archive as a reference for the mapping. The mapping can be further extended to phonetic alphabets suitable for various TTS systems.
SFST and HFST Toolkit
My g2p implementation is based on Stuttgart Finite State Transducer (SFST) and Helsinki Finite-State Technology (HFST). Both are programming language for finite state transducers which is based on extended regular expressions with variables. Written in SFST programming paradigm, the code is compiled to create an automata. HFST’s wider programming interfaces utilise this automata to provide python api, web api and command line inteface for Malayalam phonetic analyser.
Web Demo
You can now easily test the Malayalam phonetic analyser system here:
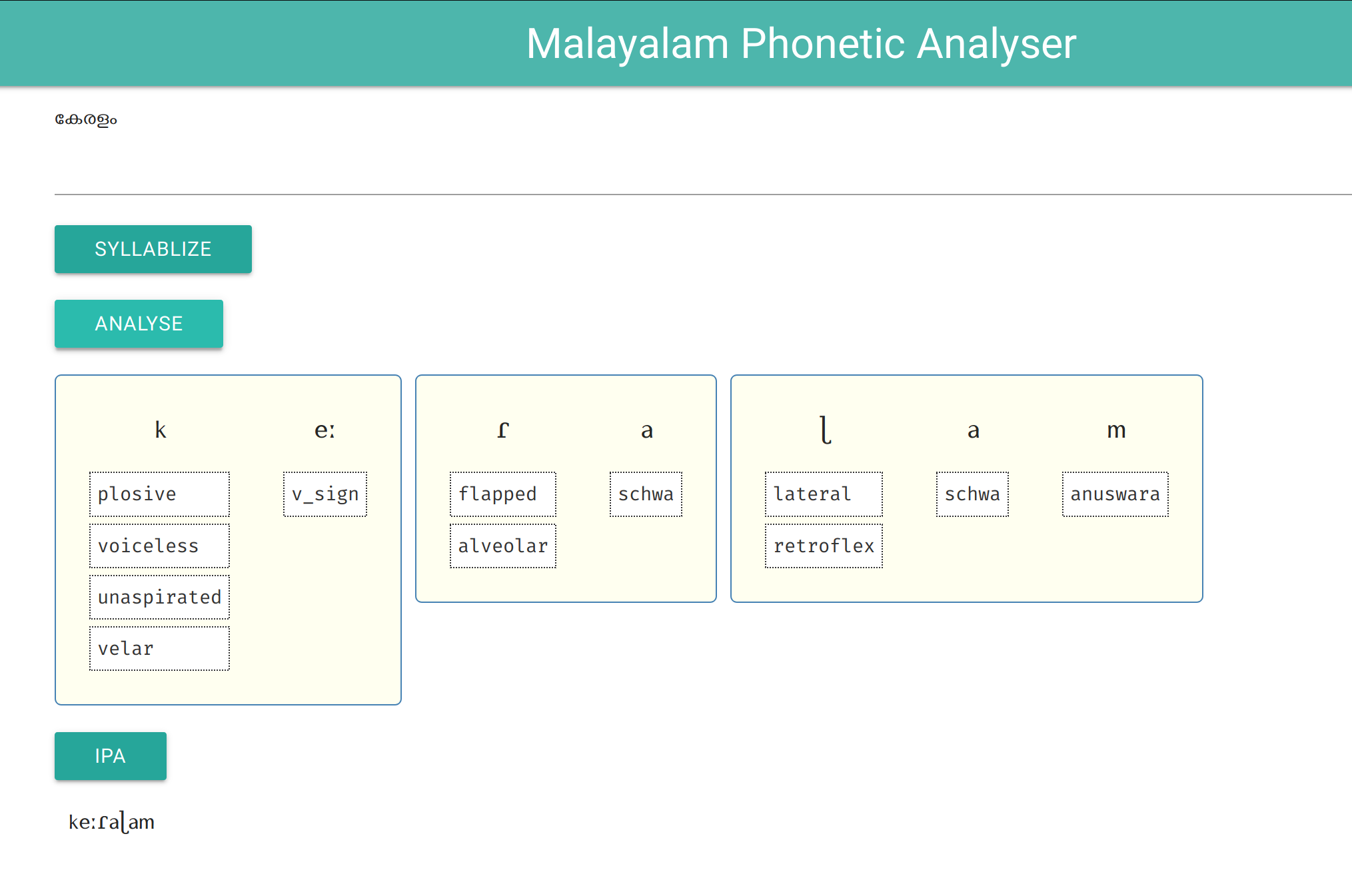
It analyses single Malayalam words and displays IPA and phonetic details. Source code and conversations can be found on project page.
Future Works
Currently,a transliteration of graphemes to IPA along with articulatory details of consonants as ’tags’ is done by this analyser. This won’t be sufficient for a speech synthesis system. Spoken Malayalam has a lot of contextual variations in phonemes from what is currently implemented. A thorough study on the same and its implementation is an immediate future plan.
Most TTS systems use their own internal phonetic represenatation. Mapping of IPA to such systems can be done, if it can be directly converted to speech by such systems.
Will update the progress here. Thanks for reading 😀.
References
- Open morphology for Finnish
- Malyalam morphological analyser using finite state transducers
- The Festvox Indic Frontend for Grapheme-to-Phoneme Conversion
- Malayalam Phonetic Archive by Thunchath Ezhuthachan Malayalam University
- IPA and sounds