Malayalam speech recognition model trained on various openly available speech and text corpora using Kaldi toolkit is now released here. It is now available for testing on the Vosk-Browser Speech Recognition Demo website. This Malayalam model can be used with Vosk speech recognition toolkit which has bindings for Java, Javascript, C# and Python.
A speech recognition architecture that works best in scenarios of limited speech data availability is called a pipeline model, where it is composed of an acoustic model, a language model and a phonetic lexicon.
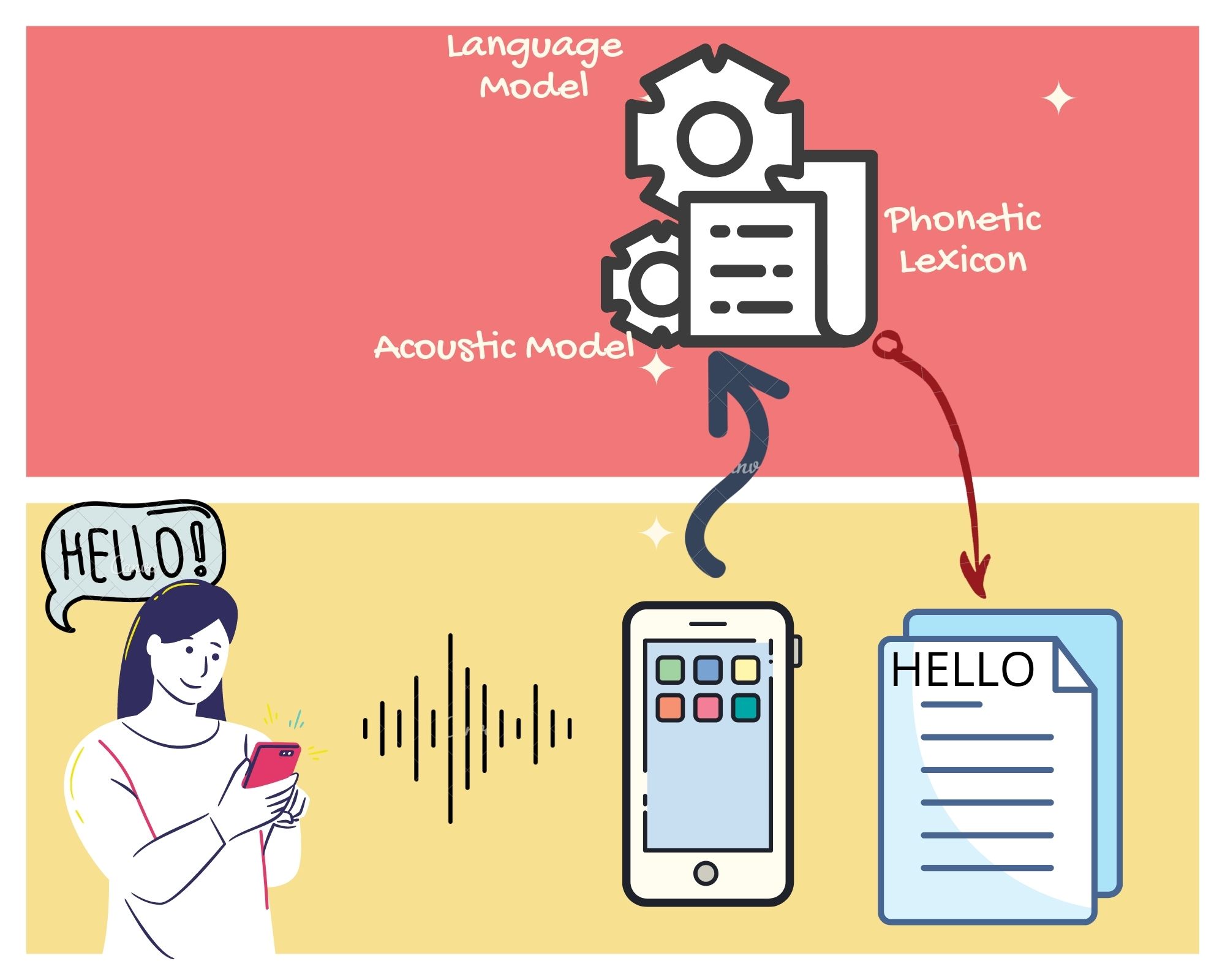
Our acoustic model is trained on approximately 18 hours of Malayalam speech using Kaldi toolkit. The N-gram language model is trained on SMC Text Corpus and the speech transcripts. The phonetic lexicon of more than 121k Malayalam words was created using Mlphon toolkit. For more details on training recipe check the repository.
Demo video