My work, Quantitative Analysis of the Morphological Complexity of Malayalam Language is accepted for presentation at the 23rd International Conference on Text, Speech and Dialogue to be held from September 8-10, 2020. The conference proceedings is published by Springer and you can read the paper here. I will share the presentation slides and video after the conference. See the associated data and code here.
This blog-post is a bit detailed discussion of the following aspects, analysed in the paper:
- Malayalam is a morphologically complex language. What does that mean?
- Is there a systematic way to measure this complexity?
- What are the corpus-linguistic parameters indicating morphological complexity?
- Types and Tokens
- Type-Token Ratio (TTR)
- Type-Token Growth Rate (TTGR)
- Moving Average Type-Token Ratio (MATTR)
- Analyse Malayalam Wikipedia dump as available from SMC corpus to compute these parameters.
- Compare these parameter values with the reported values in other Dravidian and European languages
- Implication of morphological complexity on NLP applications
By measuring the morphological complexity and comparing it against the same measurements for Dravidian languages and European languages, I show that Malayalam is morphologically more complex than them.
Morphological Complexity of Malayalam
Malayalam is a language with productive morphology. That means Malayalam words undergo inflections, derivations and compounding, producing an infinite vocabulary. For example the noun ആന (elephant) can undergo inflections by attaching suffixes to it to form words like ആനകള് (elephants), ആനയുടെ (of elephant), ആനയ്ക്ക് (for elephant) etc. A lot of words can be derived from a single word പാടുക (sing) as പാട്ട്(song), പാട്ടുകാരി(female singer), പാട്ടുകാര്(singers), പാടി(sung), പാടിയിട്ടുണ്ട് (has sung), പാടിക്കൊണ്ടിരിക്കുന്നു(is singing), പാടാം (shall sing) etc. Multiple words combining to form new words can be seen in ആനക്കുട്ടി (baby elephant), മണല്ത്തരി (sand grains) etc. These compound words can further undergo inflections and derivations. This is the reason behind the complexity (richness) of Malayalam morphology.
A native Malayalam speaker produces sufficiently complex words during natural speech with super ease. ഞാനിപ്പൊക്കൊണ്ടുവരാം is a ‘compound word’, meaning I shall bring it soon. But you will never find the word ഞാനിപ്പൊക്കൊണ്ടുവരാം in a Malayalam dictionary, because it is practically impossible to list all possible compounding, inflections and derivations of Malayalam words. So a dictionary will have only entries for the root words. Having said this, it must be intuitively clear that Malayalam is a morphologically rich language.
But this is not a feature unique to Malayalam. There are many languages in the world that follow this pattern of productive morphology. Other Dravidian languages like Tamil and Kannada, European languages of Turkish, Finnish, Dutch etc. belong to this category by varying extends.
Measuring Morphological Complexity
So Malayalam is morphologically complex. You can go on making new words to express yourselves in Malayalam. But is there a quantitative measure to indicate how much is the complexity? How do you know if its morphological complexity is comparatively higher than another language, say Finnish?
Well, there are multiple definitions for morphological complexity, but no unanimously accepted measures.
One definition by Patrick Juola follows an information theoretic approach based on Kolmogrov Complexity measure. (Read more: Measuring linguistic complexity: The morphological tier, Patrick Juola). Another approach by Bane separates word stems, affixes and signatures and defines it in terms of Description Length(DL). The number of possible inflection points, the number of inflectional categories, number of morpheme types are all indicators of morphological complexity. (Read more: Quantifying and Measuring Morphological Complexity, Max Bane). These methods involve detailed linguistic know-how, requires annotated text corpus with morpheme tags, human expert judgements or availability of an automatic tagger for the language to be analysed.
Alternatively there are corpus linguistic analysis techniques to measure morphological complexity and these techniques are proved to give results comparable to those based on typological information. (Read More: A Comparison Between Morphological Complexity Measures: Typological Data vs. Language Corpora, Christian Bentz)
The corpus linguistic parameters being analysed here are Types and Tokens.
Types and Tokens
Types and Tokens are related to word counts in a text corpus. Any element in the set of all distinct words in a text corpus is called a type and every occurrence of type in a corpus is called token.
For example there are 7 types and 9 tokens in the following sentence.
To be or not to be is the question
On the other hand, its translation in Malayalam has 4 types and 4 tokens.
വേണോ വേണ്ടയോ എന്നതാണ് ചോദ്യം
For a morphologically complex language more meanings get embedded into every wordform and diverse wordforms appear in a corpus which are seldom repeated.
Type-Token Ratio (TTR)
For the sample in English above,the ratio between types and tokens is given by:
$ TTR = \frac{Type\ Count}{Token\ Count}=\frac{7}{9} = 0.77 $
But for the Malayalam sample,
$ TTR = \frac{Type\ Count}{Token\ Count}=\frac{4}{4} = 1 $
A morphologically complex language with inflectional and agglutinative nature will have relatively less number of text tokens in a parallel corpora, but will have more number of unique types. (Read More: Comparing morphological complexity of Spanish, Otomi and Nahuatl, Ximena Gutierrez-Vasques)
Type and Token Analysis to measure morphological complexity
It is important to note that the TTR of a text sample is affected by its total length; obviously, the longer the text goes on, the more likely it is that the next word will be one that has already occurred.
For a language with simple morphology, the number of unique words(types) reaches a saturation as the total number words(tokens) under consideration increases. It means, even if you parse more and more on a text corpus, it will be difficult for you to find a word that has not appeared before. But for a language like Malayalam with productive morphology, the number of types does not actually reach a saturation level easily.
Type-Token Growth Rate is an indicator of how does the cumulative number of unique types vary with the cumulative number of total tokens parsed.
Moving Average Type Token ratio(MATTR)
In general higher the value of TTR, more will be the morphological complexity. (Read More: A Comparison Between Morphological Complexity Measures: Typological Data vs. Language Corpora, Christian Bentz).
The TTR depends largely on the length of text analysed. So another way to analyse the relative number of types and tokens are in terms of TTR on a window of specified text size. Then that window is moved over the entire span of text. The resulting values of TTR is averaged across all window positions to obtain the Moving Average Type Token ratio(MATTR).
Analyzing a Malayalam Text Corpus
We will now analyse and compare the following indicators of morphological complexity measurements on a large Malayalam text corpus.
- Type-Token Ratio (TTR)
- Type-Token Growth Rate (TTGR)
- Moving Average Type-Token Rato (TTGR)
The Corpus Used
To apply these measures and analyse these values for Malayalam, the Malayalam Wikipedia article dump, as available from SMC Malayalam corpus is used.
The corpus is cleaned up for text normalization, removal of punctuation, other language script etc. using the following script
Type Token Growth Rate Analysis for Malayalam
Once this is done, there are more than 8 million tokens in the corpora. The number of unique types in the first 1000 tokens were 805. The first 2000 tokens contained 1487 unique types. Computing this cumulatively for the 8 million tokens resulted in the following table. The interval of cumulative counts in the successive rows is not fixed. It is small initially (1000) and slowly rises(1000000).
| Tokens | Types |
|---|---|
| 1000 | 805 |
| 2000 | 1487 |
| 3000 | 2175 |
| 4000 | 2777 |
| 5000 | 3432. |
| 6000 | 4040 |
| 7000 | 4649 |
| 8000 | 5321 |
| 9000 | 5892 |
| 10000 | 6479 |
| 100000 | 44487 |
| 200000 | 75530 |
| 300000 | 103794 |
| 400000 | 128660 |
| 500000 | 153265 |
| 600000 | 176817 |
| 700000 | 198450 |
| 800000 | 219060 |
| 900000 | 241250 |
| 1000000 | 261124 |
| 2000000 | 452906 |
| 3000000 | 615515 |
| 4000000 | 769028 |
| 5000000 | 912205 |
| 6000000 | 1035903 |
| 7000000 | 1151922 |
| 8140110 | 1284652 |
Table 1: Cumulative count of the number of tokens and the unique types in them. Tabulated from the text corpus of Malayalam Wikipedia articles extracted on 1st January, 2019 available from SMC Malayalam corpus
Figure 1: Type Token Growth Rate Analysis for Malayalam, plotted from Table 1, using the data from the text corpus of Malayalam Wikipedia articles extracted on 1st January, 2019 available from SMC Malayalam corpus

The Figure 1 on the Type Token Growth Rate indicates a steep increase initially. As the token count reaches 8 million, the unique type count is around 1.2 million.
This result is comparable with that of the Type-Token Growth rate reported in the paper, Statistical Analyses of Telugu Text Corpora, G.BharadwajaKumar et. al.
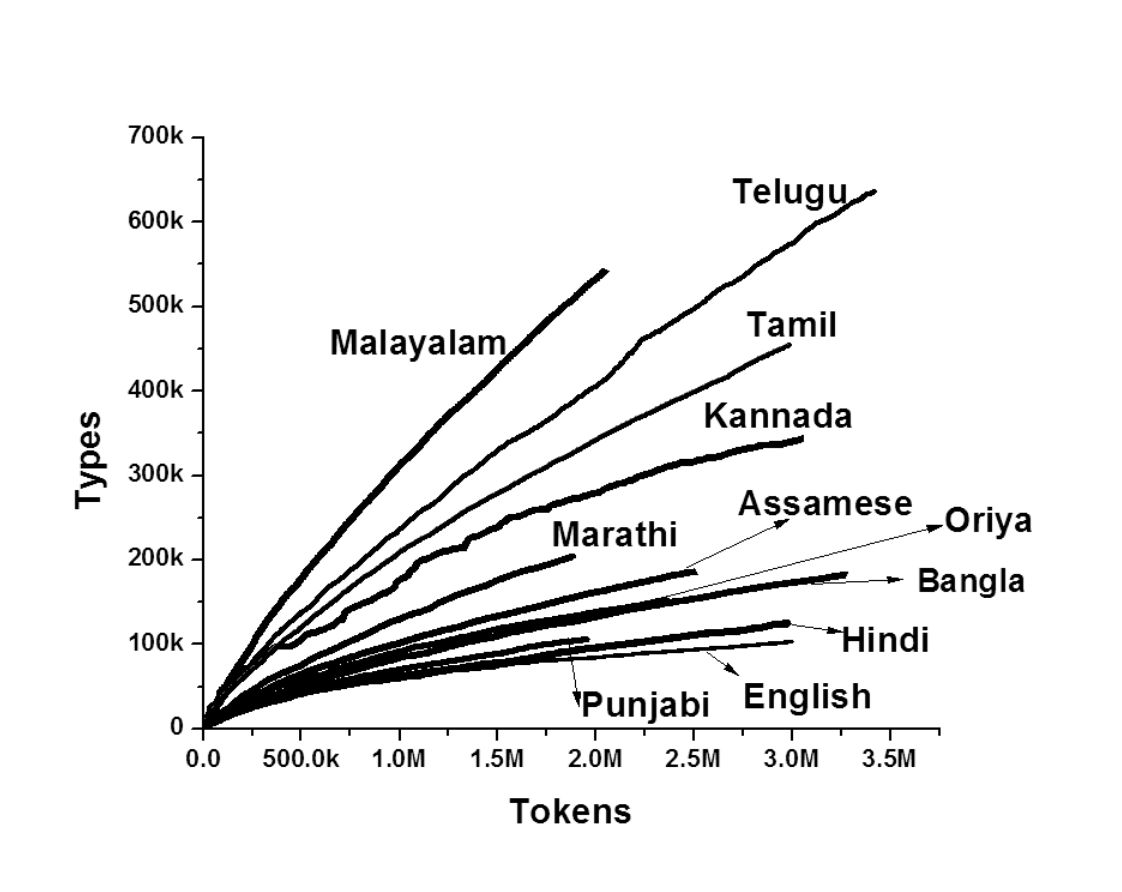
Figure 2: Type Token Growth Rate Analysis for different languages, reused from the paper Statistical Analyses of Telugu Text Corpora, G.BharadwajaKumar et. al.
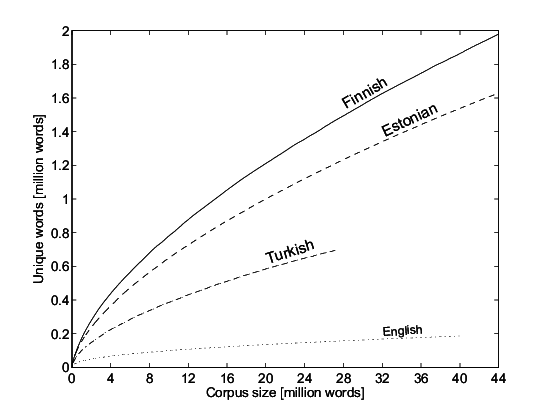
The Type-Token Growth Rate for Malayalam is higher than Finnish, as can be seen in the Figure 3 below. The number of unique types for Finnish is ~0.7 million for 8 million tokens, while that for Malayalam it is 1.2 million types per 8 million tokens.
It may also be noted that the unique type counts get saturated for English, and the graph is quite a straight line, as the token count increases.
Figure 3: Type Token Growth Rate Analysis for different languages, reused from the paper Analysis of Morph-Based Speech Recognition and the Modeling of Out-of-Vocabulary Words Across Languages, Mathias Creutz et. al.
Type-Token Ratio (TTR) for Malayalam
The ratio of the number of distinct words in a text corpus (Types) to the total word count (Tokens) is called Type Token Ratio (TTR). But it largely depends on the total length of the text being analysed. Kimmo Kettunen reports that, other methods of morphological complexity measurements involving linguistic analysis and correlates with the TTR based analysis of morphological complexity, in the study Can Type-Token Ratio be Used to Show Morphological Complexity of Languages?.
From the Malayalam Wikipedia dump from SMC text corpus, the following table of TTR is obtained.
| Number of Tokens | Number of Types | Type Token Ratio (TTR) |
|---|---|---|
| 1000 | 805 | 0.81 |
| 2000 | 1487 | 0.74 |
| 3000 | 2175 | 0.73 |
| 4000 | 2777 | 0.69 |
| 5000 | 3432 | 0.69 |
| 6000 | 4040 | 0.67 |
| 7000 | 4649 | 0.66 |
| 8000 | 5321 | 0.67 |
| 9000 | 5892 | 0.65 |
| 10000 | 6479 | 0.65 |
| 100000 | 44487 | 0.44 |
| 200000 | 75530 | 0.38 |
| 300000 | 103794 | 0.35 |
| 400000 | 128660 | 0.32 |
| 500000 | 153265 | 0.31 |
| 600000 | 176817 | 0.29 |
| 700000 | 198450 | 0.28 |
| 800000 | 219060 | 0.27 |
| 900000 | 241250 | 0.27 |
| 1000000 | 261124 | 0.26 |
| 2000000 | 452906 | 0.23 |
| 3000000 | 615515 | 0.21 |
| 4000000 | 769028 | 0.19 |
| 5000000 | 912205 | 0.18 |
| 6000000 | 1035903 | 0.17 |
| 7000000 | 1151922 | 0.16 |
| 8140110 | 1284652 | 0.16 |
Table 2: Cumulative count of the number of tokens and TTR for that token count. Tabulated from the text corpus of Malayalam Wikipedia articles extracted on 1st January, 2019 available from SMC Malayalam corpus, , containing about 8 million words.
Upon plotting the TTR details from the Table 2, results in the following Figure 4.
Figure 4: Type Token Ratio, plotted from Table 2. It uses the data from the text corpus of Malayalam Wikipedia articles extracted on 1st January, 2019 available from SMC Malayalam corpus, containing about 8 million words.
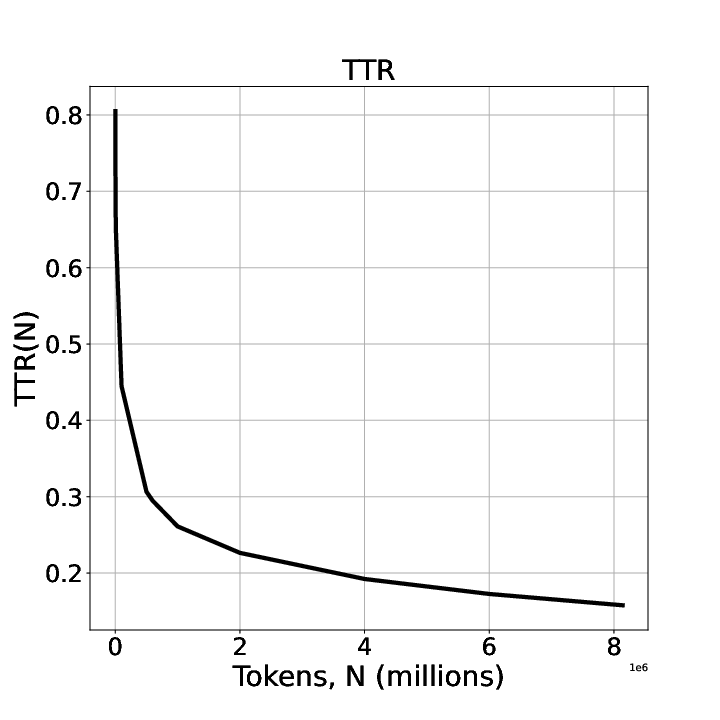
It shows the the TTR continuously decreases with increase in the number of tokens and takes a value at around 0.16, when the token count is 8 million. When the Token count is 2 million Malayalam words, the TTR is around 0.23. This is close to the value (~0.26 for a 2 million token count) reported in Statistical Analyses of Telugu Text Corpora, G. Bharadwaja Kumar et al.
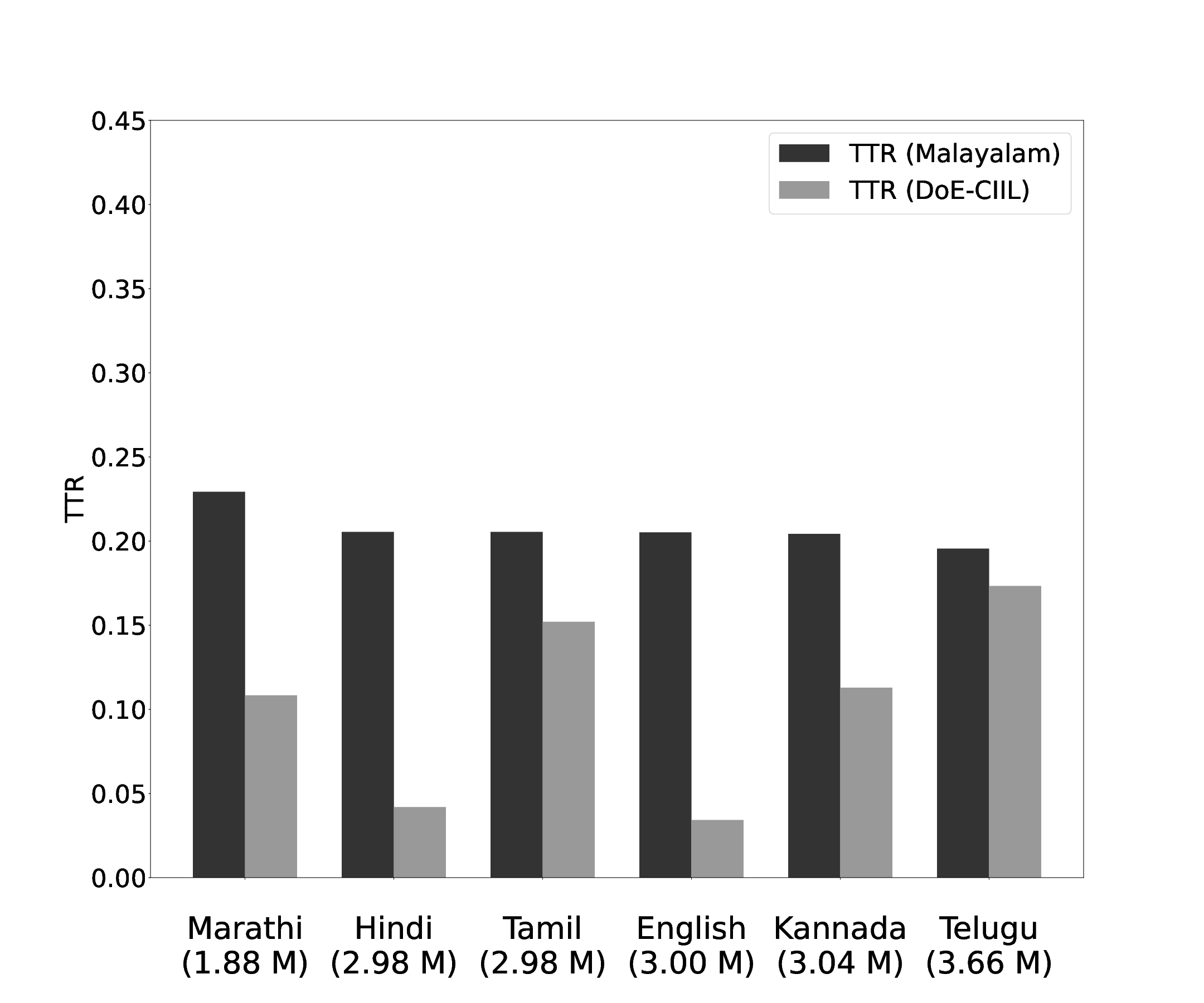
The value of TTR obtained for Malayalam with that of the reported TTR values in other languages is shown below. The corpus size of languages under study were different. So the TTR of Malayalam is computed for the same text size for which data was available for the language under comparison. The corpus size in millions is indicated against each comparison graph pair.
Figure 5: Comparison of Malayalam TTR with that of DoE-CIIL corpus as reported by Bharadwaja Kumar et al.
A similar comparison for languages from the text of European Union constitution is shown below. The data available from Kettune’s study is used to plot this graph. The corpus size in millions is indicated against each comparison graph pair.
Figure 6: Comparison of Malayalam TTR with that of European Union constitution corpus as reported by Kimmo Kettunen.
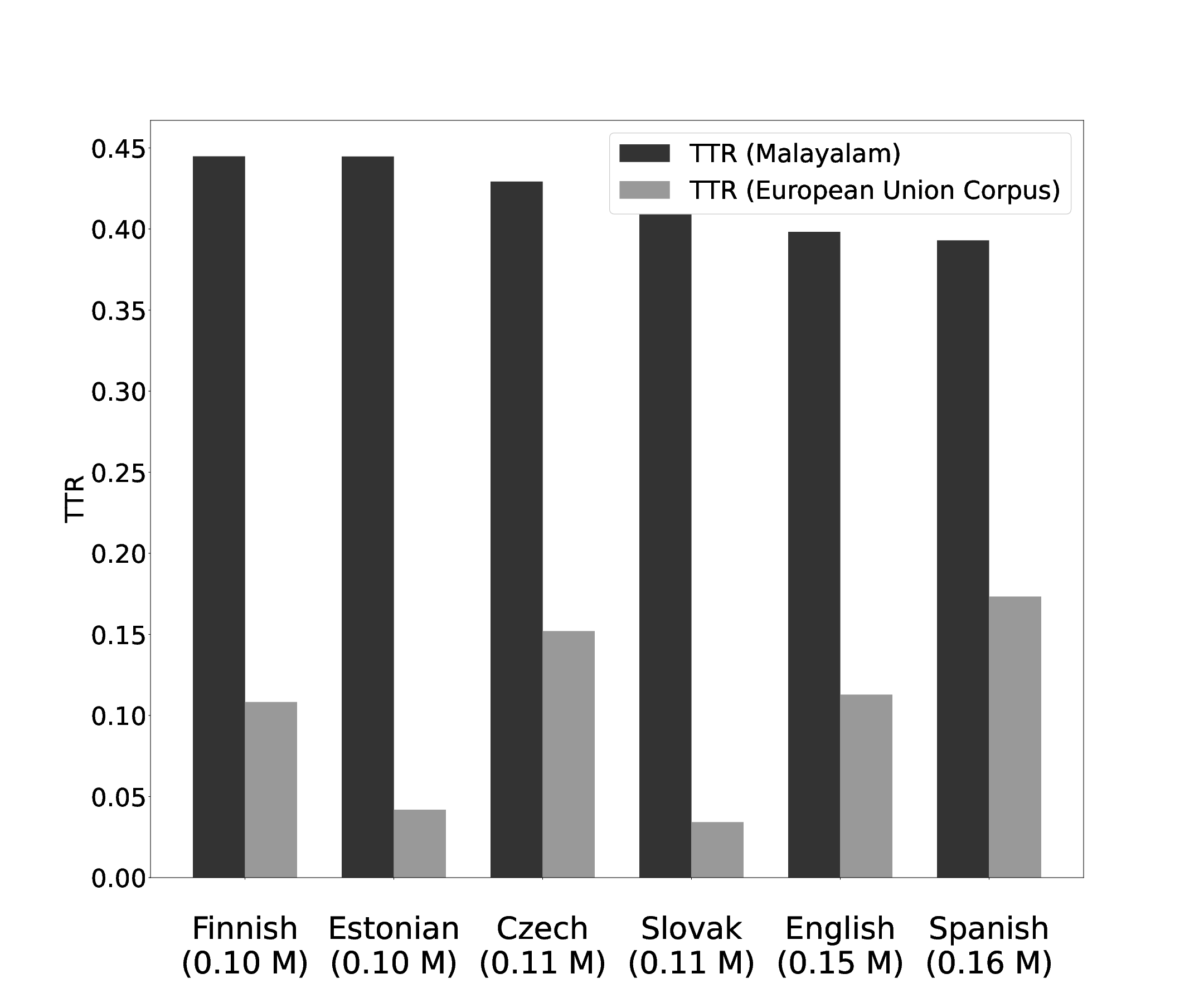
Malayalam clearly shows more morphological complexity than the European languages, Finnish, Estonian, Czech, Slovak, English and Spanish in terms of TTR values. Values of TTR obtained for Malayalam when compared with other Indian languages Marathi, Hindi, Tamil, Kannada and Telugu indicate a higher level of morphological complexity for Malayalam.
Moving Average Type Token Ratio (MATTR) for Malayalam
As seen above, TTR depends largely on the text size. So Michael A. Covington suggests using Moving-Average Type–Token Ratio(MATTR) as a measure of lexical complexity in his paper Cutting the Gordian Knot: The Moving-Average Type–Token Ratio(MATTR).
For comparison across different experiments, he suggests calculating the TTR over a smoothly moving window of size 500. The code snippet used to extract the TTR over each window position is given below:
| Token index | Number of Types | Type Token Ratio |
|---|---|---|
| 1-500 | 425 | 0.85 |
| 2-501 | 426 | 0.852 |
| 3-502 | 426 | 0.852 |
| 4-503 | 427 | 0.854 |
| 5-504 | 427 | 0.854 |
| 6-505 | 427 | 0.854 |
| 7-506 | 428 | 0.856 |
| 8-507 | 429 | 0.858 |
| 9-508 | 429 | 0.858 |
| 10-509 | 430 | 0.86 |
| 11-510 | 430 | 0.86 |
| 12-511 | 430 | 0.86 |
| .. | .. | .. |
| 871-1370 | 400 | 0.8 |
| 872-1371 | 399 | 0.798 |
| 873-1372 | 399 | 0.798 |
| 874-1373 | 399 | 0.798 |
| .. | .. | .. |
| 1000-1500 | 396 | 0.792 |
| MA-TTR | 0.834 |
Table 3: Moving Average Type Token Ratio tabulated over smoothly moving windows of token length 500, for the first 1000 window positions. Tabulated from the text corpus of Malayalam Wikipedia articles extracted on 1st January, 2019 available from SMC Malayalam corpus, containing about 8 million words.
Figure 7: Type Token Ratio, plotted from Table 3. MATTR of different sections of the corpus is also indicated.
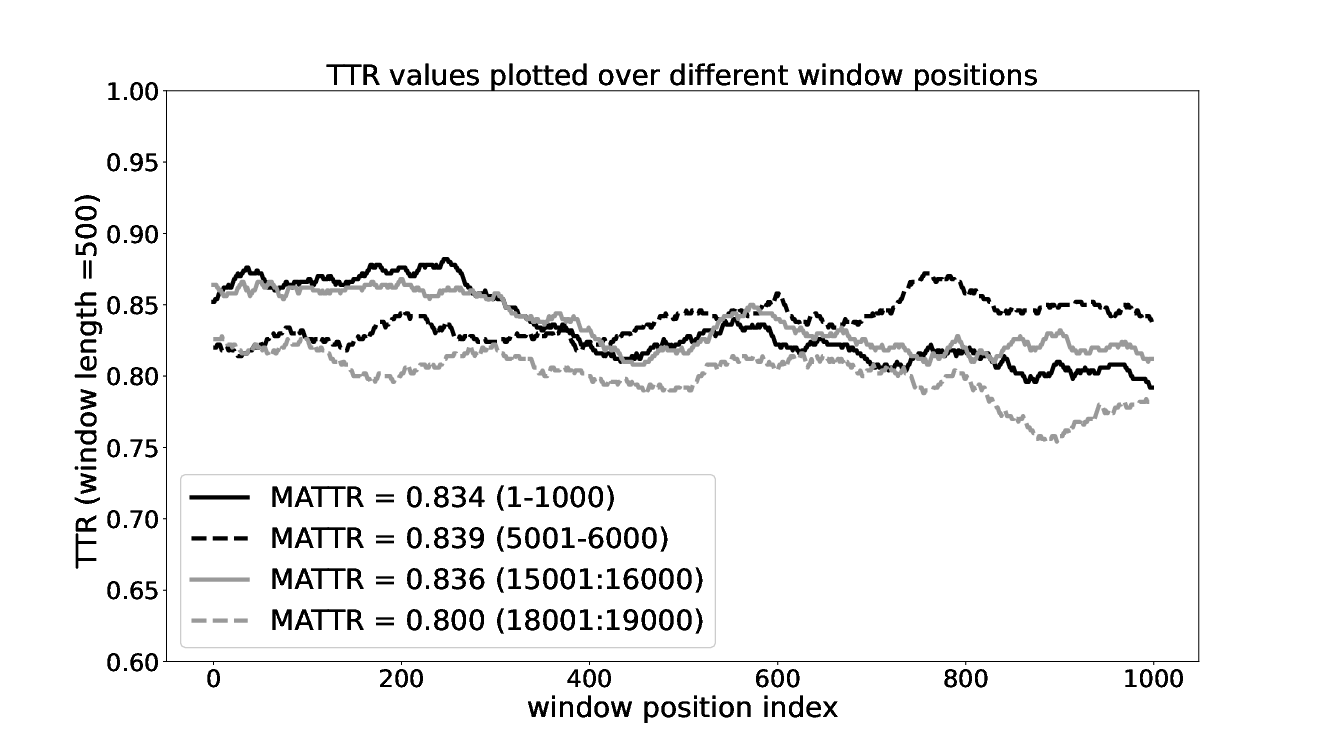
Taking the average over 1000 window positions result in an MATTR value of 0.834. The MATTR calculations of European languages by Kettunen on European Union constitution, indicates that this value is quite high. The highest reported value is for Finnish, which is 0.60. He has also noted the dependency of these values on the nature of the corpus. A more informal corpus will have more unique types in general.
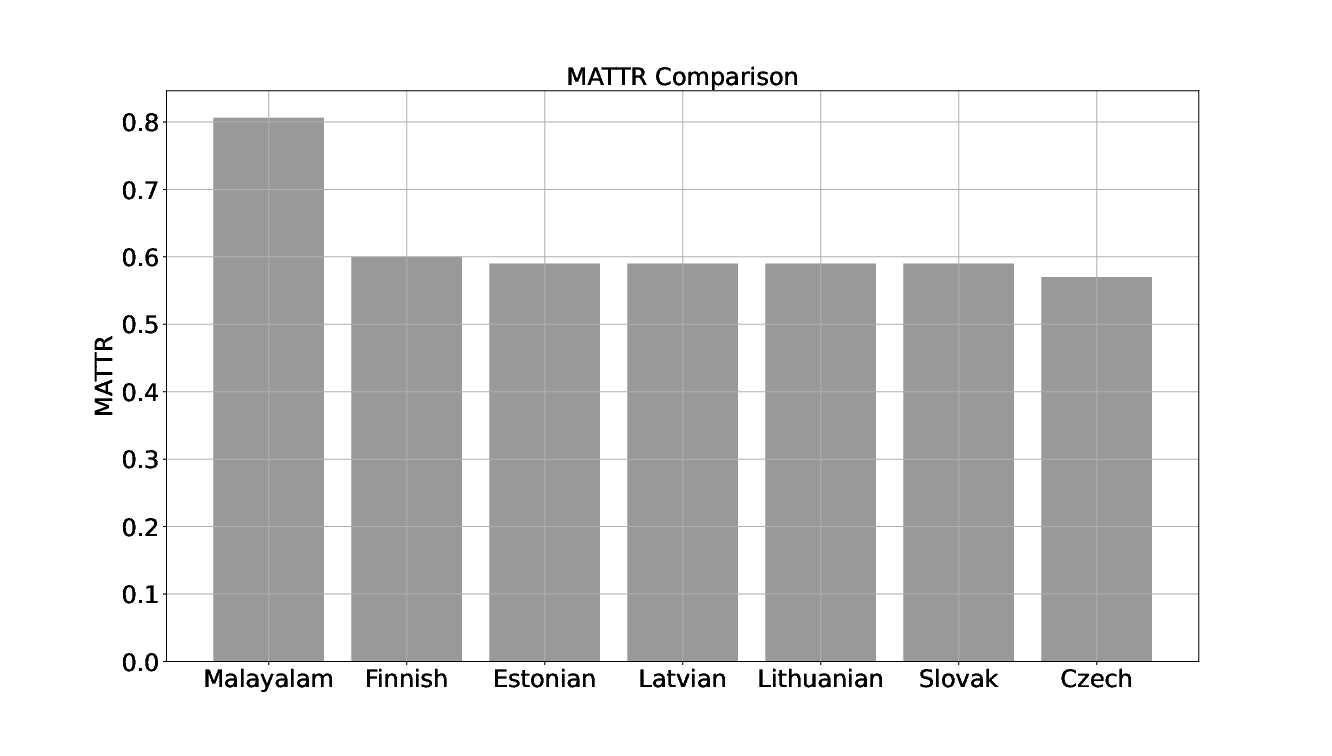
Computing MATTR with 0.1 million tokens of SMC corpus resulted in a value 0.806 for Malayalam. Kettunen has reported MATTR values on European Union constitution corpus with each language having a token count slightly above 0.1 million. A comparative graph of the MATTR values reported by Kettunen with the values obtained for Malayalam is plotted in Figure 7. It clearly indicates a higher degree of morphological complexity for Malayalam in terms of MATTR on a formal text corpus. An equivalent comparison with other Indian languages could not be done due to non availability of reported studies.
Figure 7: MATTR comparison of Malayalam with other European languages as reported by Kettunen
Reporting Morphological complexity of Malayalam
- Malayalam has an intuitively complex morphology, due to its agglutinative, inflective and derivative nature.
- A quantitative analysis on the morphological complexity of Malayalam on a formal text corpus of 8 million tokens is presented here.
- The parameters Type Token Ratio, Type Token Growth Rate, and Moving Average Type Token Ratio, have values much higher than their reported values in other morphologically complex languages.
- The study is conducted on a formal text corpus of Wikipedia text after simple cleanup and normalizations. Corpus dependency of the reported values can be analysed if a more informal corpus of web crawled content is available.
- Alternate approaches for measuring the linguistic complexity in terms of entropy and perplexity may be studied and compared with the type token parameter values.
NLP for morphologically complex languages
- The morphological complexity of Malayalam indicates its practically infinite vocabulary
- English has a pronunciation dictionary like CMUDict, used in general purpose TTS and ASR applications. But such a static pronunciation dictionary can not handle the infinite vocabulary of Malayalam.
- Language modeling is a crucial NLP task in predictive text entry, automatic speech recognition, POS tagging and machine translation.
- Due infinite vocabulary and free word order, statistical n-gram language modeling is not truly meaningful for Malayalam. For the same reasons, neural language models would also be difficult for Malayalam.
- Having formally defined the morphological complexity of Malayalam, this study urges to look for specialized techniques to solve various NLP problems in methods different from the solutions already available for English.